以下为译文,原文地址:http://www.codeproject.com/Articles/1006192/JavaScript-Summary
简介
JavaScript是一门面向对象的动态语言,他一般用来处理以下任务:
- 修饰网页
- 生成HTML和CSS
- 生成动态HTML内容
- 生成一些特效
- 提供用户交互接口
- 生成用户交互组件
- 验证用户输入
- 自动填充表单
- 能够读取本地或者远程数据的前端应用程序,例如http://web-engineering.info/JsFrontendApp-Book
- 通过Nodejs实现像JAVA,C#,C++一样的服务端程序
- 实现分布式WEB程序,包括前端和服务端
当前浏览器所支持的JavaScript的版本被称为“ECMAScript的5.1”,或简单的“ES5”,但接下来的两个版本,称为“ES6”和“ES7”(或“ES2015”和“ES2016”,新版以本年命名),有很多的附加功能和改进的语法,是非常值得期待的(并已部分被当前的浏览器和后端JS的环境支持)。
此篇博文,引自《Building Front-End Web Apps with Plain JavaScript》一书。
JavaScript类型和常量
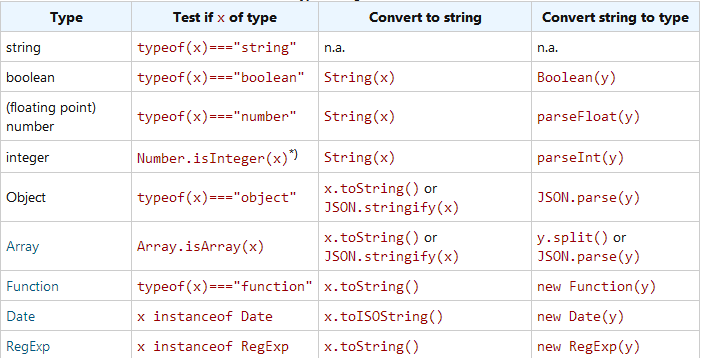
JS有3个值类型:string,number和boolean,我们可以用一个变量v保存不同类型的值用来和typeof(v)比较, typeof(v)===”number”。
JS有5个引用类型:Object, Array, Function, Date 和 RegExp。数组,函数,日期和正则表达式是特殊类型的对象,但在概念上,日期和正则表达式是值类型,被包装成对象形式体现。
变量,数组,函数的参数和返回值都可以不声明,它们通常不会被JavaScript引擎检查,会被自动进行类型转换。
变量值可能为:
- 数据,如string,number,boolean
- 对象的引用:如普通对象,数组,函数,日期,正则表达式
- 特殊值null,其通常用作用于初始化的对象变量的默认值
- 特殊值undefined,已经声明但没有初始化的初始值
string是Unicode字符序列。字符串常量会被单引号或双引号包裹着,如“Hello world!”,“A3F0’,或者空字符串””。两个字符串表达式可以用+操作符连接,并可通过全等于比较:
if (firstName + lastName === "James Bond") 字符串的字符数量可以通过length属性获得:
console.log( "Hello world!".length); // 12所有的数字值都是在64位浮点数字。整数和浮点数之间没有明确的类型区别。如果一个数字常量不是数字,可以将其值设置为NaN(“not a number”),它可以用isNaN方法来判断。
不幸的是,直到ES6才有Number.isInteger方法,用于测试一个数是不是一个整数。因此在还不支持它的浏览器中,为确保一个数字值是一个整数,或者一个数字的字符串被转换为一个整数,就必须使用parseInt函数。类似地,包含小数的字符串可用与parseFloat方法转换。将一个数子n转换成字符串,最好的方法是使用String(n)。
就像Java,我们也有两个预先定义好的布尔型值,true与false,以及布尔运算符符号: ! (非),&&(与),||(或)。当非布尔型值与布尔型值比较时,非布尔型值会被隐式转换。空字符串,数字0,以及undefined和null,会被转换为false,其他所有值会转换为true。
通常我们需要使用全等符号符号(===和!==)而不是==和!=。否则,数字2是等于的字符串“2”的, (2 == “2”) is true
VAR= [] 和var a = new Array() 都可以定义一个空数组。(二胡:推荐前者)
VAR O ={} 和 var o = new Obejct() 都可以定义个空对象(二胡:还是推荐前者)。注意,一个空对象{}不是真的空的,因为它包含的Object.prototype继承属性。所以,一个真正的空对象必须以Null为原型, var o = Object.create(null)。
表1 类型测试和转换
变量作用域
在JavaScript的当前版本ES5,有两种范围变量:全局作用域和函数作用域,没有块作用域。因此,应该避免声明在块内声明变量。
function foo() {
for (var i=0; i < 10; i++) {
... // do something with i
}
}我们应该这样写
function foo() {
var i=0;
for (i=0; i < 10; i++) {
... // do something with i
}
}所有变量应在函数的开始声明。只有在JavaScript的下一个版本ES6中,我们可以用let关键词声明一个块级变量。
严格模式
从ES5开始,我们可以使用严格模式,获得更多的运行时错误检查。例如,在严格模式下,所有变量都必须进行声明。给未声明的变量赋值抛出异常。
我们可以通过键入下面的语句作为一个JavaScript文件或script元素中的第一行开启严格模式:’use strict’;
通常建议您使用严格模式,除非你的代码依赖于与严格的模式不兼容的库。
不同类型的对象
JS对象与传统的OO/UML对象不同。它们可以不通过类实例化而来。它们有属性、方法、键值对三种扩展。
JS对象可以直接通过JSON产生,而不用实例化一个类。
var person1 = { lastName:"Smith", firstName:"Tom"};
var o1 = Object.create( null); // an empty object with no slots对象属性可以以两种方式获得:
- 使用点符号(如在C ++/ Java的):
person1.lastName = “Smith”
- 使用MAP方式
person1[“lastName”] = “Smith”
JS对象有不同的使用方式。这里有五个例子:
- 记录,例如,
var myRecord = {firstName:”Tom”, lastName:”Smith”, age:26}
- MAP(也称为“关联数组”,“词典”或其他语言的“哈希表”)
var numeral2number = {“one”:”1″, “two”:”2″, “three”:”3″}
- 非类型化对象
var person1 = { lastName: "Smith", firstName: "Tom", getFullName: function () { return this.firstName +" "+ this.lastName; } }; - 命名空间
var myApp = { model:{}, view:{}, ctrl:{} };
可以由一个全局变量形式来定义,它的名称代表一个命名空间前缀。例如,上面的对象变量提供了基于模型 – 视图 – 控制器(MVC)架构模式,我们有相应的MVC应用程序的三个部分。
- 正常的类
数组
可以用一个JavaScript数组文本进行初始化变量:
var a = [1,2,3];
因为它们是数组列表,JS数组可动态增长:我们可以使用比数组的长度更大的索引。例如,上面的数组变量初始化后,数组长度为3,但我们仍然可以操作第5个元素 a[4] = 7;
我们可以通过数组的length属性得到数组长度:
`for (i=0; i < a.length; i++) { console.log(a[i]);} //1 2 3 undefined 7 ` 我们可以通过 Array.isArray(a) 来检测一个变量是不是数组。
通过push方法给数组追加元素:a.push( newElement);
通过splice方法,删除指定位置的元素:a.splice( i, 1);
通过indexOf查找数组,返回位置或者-1:if (a.indexOf(v) > -1) …
通过for或者forEach(性能弱)遍历数组:
var i=0;
for (i=0; i < a.length; i++) {
console.log( a[i]);
}
a.forEach(function (elem) {
console.log( elem);
}) 通过slice复制数组:var clone = a.slice(0);
Maps
map(也称为“散列映射”或“关联数组’)提供了从键及其相关值的映射。一个JS map的键是可以包含空格的字符串:
var myTranslation = {
"my house": "mein Haus",
"my boat": "mein Boot",
"my horse": "mein Pferd"
}通过Object.keys(m)可以获得map中所有的键:
var i=0, key="", keys=[];
keys = Object.keys( myTranslation);
for (i=0; i < keys.length; i++) {
key = keys[i];
alert('The translation of '+ key +' is '+ myTranslation[key]);
}通过直接给不存在的键赋值来新增元素:
myTranslation["my car"] = "mein Auto";通过delete删除元素:
delete myTranslation["my boat"];通过in搜索map:
`if ("my bike" in myTranslation) ...`通过for或者forEach(性能弱)和Object.keys()遍历map:
var i=0, key="", keys=[];
keys = Object.keys( m);
for (i=0; i < keys.length; i++) {
key = keys[i];
console.log( m[key]);
}
Object.keys( m).forEach( function (key) {
console.log( m[key]);
}) 通过 JSON.stringify 将map序列化为JSON字符串,再JSON.parse将其反序列化为MAP对象 来实现复制:
var clone = JSON.parse( JSON.stringify( m)) 请注意,如果map上只包含简单数据类型或(可能嵌套)数组/map,这种方法效果很好。在其他情况下,如果map包含Date对象,我们必须写我们自己的clone方法。
Functions
JS函数是特殊的JS的对象,它具有一个可选的名字属性和一个长度属性(参数的数目)。我们可以这样知道一个变量是不是一个函数:
if (typeof( v) === "function") {...}JS函数可以保存在变量里、被当作参数传给其他函数,也可以被其他函数作为返回值返回。JS可以被看成一个函数式语言,函数在里面可以说是一等公民。
正常的定义函数方法是用一个函数表达式给一个变量赋值:
var myFunction = function theNameOfMyFunction () {...}
function theNameOfMyFunction () {...}其中函数名(theNameOfMyFunction)是可选的。如果省略它,其就是一个匿名函数。函数可以通过引用其的变量调用。在上述情况下,这意味着该函数通过myFunction()被调用,而不是通过theNameOfMyFunction()调用。
JS函数,可以嵌套内部函数。闭包机制允许在函数外部访问函数内部变量,并且创建闭包的函数会记住它们。
当执行一个函数时,我们可以通过使用内置的arguments参数,它类似一个参数数组,我们可以遍历它们,但由于它不是常规数组,forEach无法遍历它。arguments参数包含所有传递给函数的参数。我们可以这样定义一个不带参数的函数,并用任意数量的参数调用它,就像这样:
var sum = function () {
var result = 0, i=0;
for (i=0; i < arguments.length; i++) {
result = result + arguments[i];
}
return result;
};
console.log( sum(0,1,1,2,3,5,8)); // 20prototype原型链可以访问函数中的每一个元素,如Array.prototype.forEach(其中Array代表原型链中的数组的构造函数)。
var numbers = [1,2,3]; // create an instance of Array
numbers.forEach( function (n) {
console.log( n);
});我们还可以通过原型链中的prototype.call方法来处理:
var sum = function () {
var result = 0;
Array.prototype.forEach.call( arguments, function (n) {
result = result + n;
});
return result;
};Function.prototype.apply是Function.prototype.call的一个变种,其只能接受一个参数数组。
立即调用的JS函数表达式优于使用纯命名对象,它可以获得一个命名空间对象,并可以控制其变量和方法哪些可以外部访问,哪些不是。这种机制也是JS模块概念的基础。在下面的例子中,我们定义了一个应用程序,它对外暴露了指定的元素和方法:
myApp.model = function () {
var appName = "My app's name";
var someNonExposedVariable = ...;
function ModelClass1 () {...}
function ModelClass2 () {...}
function someNonExposedMethod (...) {...}
return {
appName: appName,
ModelClass1: ModelClass1,
ModelClass2: ModelClass2
}
}(); // immediately invoked这种模式在WebPlatform.org被当作最佳实践提及:https://docs.webplatform.org/wiki/tutorials/javascript_best_practices
定义和使用类
类是在面向对象编程的基础概念。对象由类实例化而来。一个类定义了与它创建的对象的属性和方法。
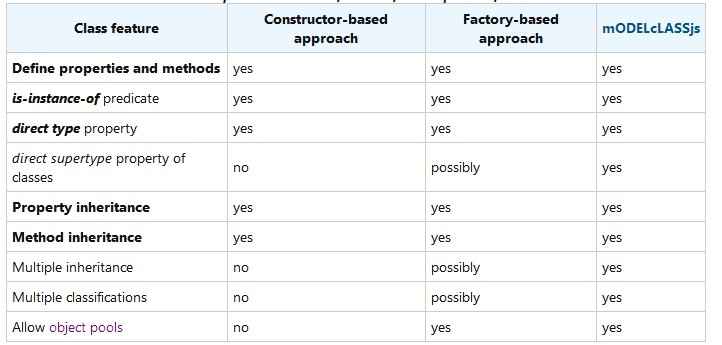
目前在JavaScript中没有明确的类的概念。JavaScript中定义类有很多不同的模式被提出,并在不同的框架中被使用。用于定义类的两个最常用的方法是:
构造函数法,它通过原型链方法来实现继承,通过new创建新对象。这是Mozilla的JavaScript指南中推荐的经典方法。
工厂方法:使用预定义的Object.create方法创建类的新实例。在这种方法中,基于构造函数继承必须通过另一种机制来代替。
当构建一个应用程序时,我们可以使用这两种方法创建类,这取决于应用程序的需求 。mODELcLASSjs是一个比较成熟的库用来实现工厂方法,它有许多优点。(基于构造的方法有一定的性能优势)
ES6中构造函数法创建类
在ES6,用于定义基于构造函数的类的语法已推出(新的关键字类的构造函数,静态类和超类)。这种新的语法可以在三个步骤定义一个简单的类。
基类Person 定义了两个属性firstName 和lastName,以及实例方法toString和静态方法checkLastName:
class Person {
constructor( first, last) {
this.firstName = first;
this.lastName = last;
}
toString() {
return this.firstName + " " +
this.lastName;
}
static checkLastName( ln) {
if (typeof(ln)!=="string" ||
ln.trim()==="") {
console.log("Error: " +
"invalid last name!");
}
}
}类的静态属性如下定义:
Person.instances = {};一个子类定义的附加属性和可能会覆盖超类的方法:
class Student extends Person {
constructor( first, last, studNo) {
super.constructor( first, last);
this.studNo = studNo;
}
// method overrides superclass method
toString() {
return super.toString() + "(" +
this.studNo +")";
}
}ES5中构造函数法创建类
在ES5,我们可以以构造函数的形式定义一个基于构造函数的类结构,下面是Mozilla的JavaScript指南中推荐的编码模式。此模式需要七个步骤来定义一个简单的类结构。由于这种复杂的模式可能很难记住,我们可能需要使用cLASSjs之类的库来帮助我们。
首先定义构造函数是隐式创建一个新的对象,并赋予它相应的值:
function Person( first, last) {
this.firstName = first;
this.lastName = last;
}这里的this指向新创建的对象。
在原型中定义实例方法:
Person.prototype.toString = function () {
return this.firstName + " " + this.lastName;
}可以在构造函数中定义静态方法,也可以用.直接定义:
Person.checkLastName = function (ln) {
if (typeof(ln)!=="string" || ln.trim()==="") {
console.log("Error: invalid last name!");
}
}定义静态属性:
Person.instances = {};定义子类并增加属性:
function Student( first, last, studNo) {
// invoke superclass constructor
Person.call( this, first, last);
// define and assign additional properties
this.studNo = studNo;
}通过Person.call( this, …) 来调用基类的构造函数。
将子类的原型链改为基类的原型链,以实现实例方法的继承(构造函数得改回来):
// Student inherits from Person
Student.prototype = Object.create(
Person.prototype);
// adjust the subtype's constructor property
Student.prototype.constructor = Student;通过Object.create( Person.prototype) 我们基于 Person.prototype创建了一个新的对象原型。
定义覆盖基类方法的子类方法:
Student.prototype.toString = function () {
return Person.prototype.toString.call( this) +
"(" + this.studNo + ")";
};最后通过new关键字来实例化一个类
var pers1 = new Person("Tom","Smith");JavaScript的prototype
prototype是函数的一个属性(每个函数都有一个prototype属性),这个属性是一个指针,指向一个对象。它是显示修改对象的原型的属性。
__proto__是一个对象拥有的内置属性(prototype是函数的内置属性。__proto__是对象的内置属性),是JS内部使用寻找原型链的属性。
每个对象都有个constructor属性,其指向的是创建当前对象的构造函数。

工厂模式创建类
在这种方法中,我们定义了一个JS对象Person,并在其内部定义了一个create方法用来调用Object.create来创建类。
var Person = {
name: "Person",
properties: {
firstName: {range:"NonEmptyString", label:"First name",
writable: true, enumerable: true},
lastName: {range:"NonEmptyString", label:"Last name",
writable: true, enumerable: true}
},
methods: {
getFullName: function () {
return this.firstName +" "+ this.lastName;
}
},
create: function (slots) {
// create object
var obj = Object.create( this.methods, this.properties);
// add special property for *direct type* of object
Object.defineProperty( obj, "type",
{value: this, writable: false, enumerable: true});
// initialize object
Object.keys( slots).forEach( function (prop) {
if (prop in this.properties) obj[prop] = slots[prop];
})
return obj;
}
}; 这样,我们就有了一个Person的工厂类,通过调用create方法来实例化对象。
var pers1 = Person.create( {firstName:"Tom", lastName:"Smith"});