
太乙三清凡夫始,灵台通明身自轻。
抛却凡界三千劫,飞身跃步入虚清。
意守丹田凝神思,凡尘往事眼中现。
玄关聚灵化为气,气游经络通元神。
平心静气抚杂念,抱元守一去心魔。
观光聚性入太虚,凝神气穴心神寂。
聚气炼神法自然,吞液炼精内阳生。
待到丹田生气穴,炼精化气筑基成。
气足开关八脉通,周天运功灵气足。
内视泥丸灵光现,静功有道入天门。
太上忘情非无情,看透凡情凝道心。
道行浅薄不足虑,斩除心魔法自成。
乾坤在手潜心修,万法随心任我行。
修仙之道漫且长,自古无人少心魔。
所谓幻象多精妙,万千情景如真相。
万相皆空灵台通,身具般若万邪避。
妙法妙音万法空,真相真形心中存。
浩然之气比长虹,贯日斩邪术永存。
周天大衍灵目开,看穿虚空见大道。
水火既济百病消,德高寿隆与天齐。
性命双修精气神,谨固牢藏休漏泄。
摒除邪欲得清凉,好向丹台赏明月。
阴阳调和天人一,方能火里种金莲。
攒聚五行知生克,观得天命可忘情。
太上忘情为有情,羽化升仙道无极。
SQL Server 聚合函数算法优化技巧
Standardv博客前言
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期。Sql server聚合函数对一组值执行计算并返回单一的值。聚合函数对一组值执行计算,并返回单个值。除了 COUNT 以外,聚合函数都会忽略空值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。
v1.写在前面
如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客。sql server 基础教程。
本文中所有数据演示都是用Microsoft官方示例数据库:Northwind,至于Northwind大家也可以在网上下载。至于下载方法MSDN已经有了详细的说明了,这里就不多说了。
v2.Sql server标量聚合
2.1.概念:
在只包含聚合函数的 SELECT 语句列列表中指定的一种聚合函数(如 MIN()、MAX()、COUNT()、SUM() 或 AVG())。当列列表只包含聚合函数时,则结果集只具有一个行给出聚合值,该值由与 WHERE 子句谓词相匹配的源行计算得到。
2.2.探索标量聚合:
我们先用Sql server的”包括实际的执行计划”来看看一个简单的流聚合COUNT()来看看表里数据所有的行数。
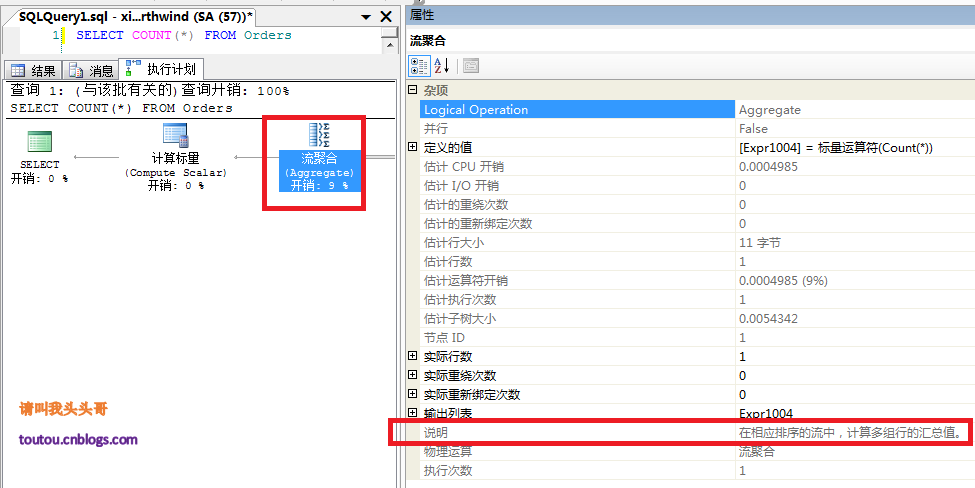 再通过SET SHOWPLAN_ALL ON(关于输出中包含的列更多信息可以在链接中查看)来看看有关语句执行情况的详细信息,并估计语句对资源的需求。
再通过SET SHOWPLAN_ALL ON(关于输出中包含的列更多信息可以在链接中查看)来看看有关语句执行情况的详细信息,并估计语句对资源的需求。
通过SET SHOWPLAN_ALL ON我们来看看COUNT()具体做了那些事情:
- 索引扫描:扫描当前表的行数
- 流计算:计算行数的数量
- 计算标量:将流计算出来的结果转化为适当的类型。(因为索引扫描出来的结果是根据表中数据的大小决定的,如果表中数据很多的话,COUNT是int类型就会有问题,所以在最终返回的时候需要将默认类型(数值一般默认类型是Big)转成int类型。)
- 小结:通过SET SHOWPLAN_ALL ON我们可以查看Sql server聚合函数在给我们呈现最终效果的时候,为这个效果做了些什么事情。

2.3.标量聚合优化技巧:
我们通过两个比较简单的sql查询来看看他们的区别
SELECT COUNT(DISTINCT ShipCity) FROM Orders SELECT COUNT(DISTINCT OrderID) FROM Orders

从上图中可以看到,其实这两个查询从语句上来说没什么太大的区别,但是为什么开销会不一样,一个是查询城市一个是查询订单号。这是因为其实DISTINCT对于OrderID查询来说,是没有什么意义的,因为OrderID是主键,是不会有重复的。而ShipCity是会有重复的,Sql server的去重机制在去重的时候,会有一个排序的过程。这个排序还是比较消耗资源的。
对于数据量比较大的表其实不是很建议对大表排序或者对大表的某个重复次数多的字段去重运算。所以我们这里可以对ShipCity进行优化一下。可以对ShipCity创建一个非聚集索引。
CREATE INDEX Index_ShipCity On Orders(ShipCity desc) go

从上图中可以看到,加了索引以后COUNT(DISTINCT ShipCity)的查询变成了两个流聚合,而没有了排序,节省了开销。
总结:对于标量聚合从上面的例子大家可以看到,标量聚合优缺点很明显:
- Sql server标量聚合优点:算法比较简单直观,适合非重复值的聚合操作。
- Sql server标量聚合缺点:性能较差(需要排序),不适合重复值的聚合操作。
优化技巧:
- 尽量避免排序产生
- 将分组字(GROUP BY)段锁定在索引覆盖范围内
v3.Sql server哈希聚合
3.1.概念:
哈希(Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
哈希聚合的内部实现方法和哈希连接的实现机制一样,需要哈希函数的内部运算,形成不同的哈希值,依次并行扫描数据形成聚合值。
3.2.背景:
为了解决流聚合的不足,应对大数据的操作,所以哈希聚合就诞生了。
3.3.分析:
来看看两个简单的查询。

ShipCountry和CustomerID的分组查询看上去很类似,但是为什么执行计划会不同呢?这是因为ShipCountry包含了大量的重复值,CustomerID重复值非常少,所以Sql server系统给ShipCountry推送的哈希聚合,而CustomerID推送的是流聚合。也就是说Sql server系统会动态的根据查询的情况选择合适的聚合方式。所以我们在做SQL优化的时候不能仅根据SQL语句来优化,还得结合具体数据分布的环境。
v4.运算过程监控指标
4.1.监控元素:
- 可视化查看运行时间
- T-sql语句查询时间
- 占用内存
- T-sql语句查询IO
4.2.可视化查看运行时间:

4.3.T-sql语句查询时间:

4.4.占用内存:

4.5.T-sql语句查询IO:

关于监控元素还有很多,这里就列举几个。
v博客总结
SQL Server 聚合函数算法优化技巧差不多就介绍到这里,如果有对sql语句优化感兴趣的可以看这篇博客。sql server之数据库语句优化
http://www.cnblogs.com/toutou/p/5002996.html
SQL Server优化之SQL语句优化
Standard一切都是为了性能,一切都是为了业务
一、查询的逻辑执行顺序
(1) FROM left_table
(3) join_type JOIN right_table (2) ON join_condition
(4) WHERE where_condition
(5) GROUP BY group_by_list
(6) WITH {cube | rollup}
(7) HAVING having_condition
(8) SELECT (9) DISTINCT (11) top_specification select_list
(9) ORDER BY order_by_list
标准的 SQL 的解析顺序为:
(1) FROM 子句 组装来自不同数据源的数据
(2) WHERE 子句 基于指定的条件对记录进行筛选
(3) GROUP BY 子句 将数据划分为多个分组
(4) 使用聚合函数进行计算
(5) 使用HAviNG子句筛选分组
(6) 计算所有的表达式
(7) 使用ORDER BY对结果集进行排序
二、执行顺序
1. FROM:对FROM子句中前两个表执行笛卡尔积生成虚拟表vt1
2. ON: 对vt1表应用ON筛选器只有满足 join_condition 为真的行才被插入vt2
3. OUTER(join):如果指定了 OUTER JOIN保留表(preserved table)中未找到的行将行作为外部行添加到vt2,生成t3,如果from包含两个以上表,则对上一个联结生成的结果表和下一个表重复执行步骤和步骤直接结束。
4. WHERE:对vt3应用 WHERE 筛选器只有使 where_condition 为true的行才被插入vt4
5. GROUP BY:按GROUP BY子句中的列列表对vt4中的行分组生成vt5
6. CUBE|ROLLUP:把超组(supergroups)插入vt6,生成vt6
7. HAVING:对vt6应用HAVING筛选器只有使 having_condition 为true的组才插入vt7
8. SELECT:处理select列表产生vt8
9. DISTINCT:将重复的行从vt8中去除产生vt9
10. ORDER BY:将vt9的行按order by子句中的列列表排序生成一个游标vc10
11. TOP:从vc10的开始处选择指定数量或比例的行生成vt11 并返回调用者
看到这里,那么用过Linq to SQL的语法有点相似啊?如果我们我们了解了SQL Server执行顺序,那么我们就接下来进一步养成日常SQL的好习惯,也就是在实现功能的同时有考虑性能的思想,数据库是能进行集合运算的工具,我们应该尽量的利用这个工具,所谓集合运算实际就是批量运算,就是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。
三、只返回需要的数据
返回数据到客户端至少需要数据库提取数据、网络传输数据、客户端接收数据以及客户端处理数据等环节,如果返回不需要的数据,就会增加服务器、网络和客户端的无效劳动,其害处是显而易见的,避免这类事件需要注意:
A、横向来看
(1) 不要写SELECT * 的语句,而是选择你需要的字段。
(2) 当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
如有表table1(ID,col1)和table2(ID,col2) Select A.ID, A.col1, B.col2 -- Select A.ID, col1, col2 –不要这么写,不利于将来程序扩展 from table1 A inner join table2 B on A.ID=B.ID Where …
B、纵向来看
(1) 合理写WHERE子句,不要写没有WHERE的SQL语句。
(2) SELECT TOP N * – 没有WHERE条件的用此替代。
四、尽量少做重复的工作
A、控制同一语句的多次执行,特别是一些基础数据的多次执行是很多程序员很少注意的。
B、减少多次的数据转换,也许需要数据转换是设计的问题,但是减少次数是程序员可以做到的。
C、杜绝不必要的子查询和连接表,子查询在执行计划一般解释成外连接,多余的连接表带来额外的开销。
D、合并对同一表同一条件的多次UPDATE,比如
UPDATE EMPLOYEE SET FNAME='HAIWER' WHERE EMP_ID=' VPA30890F'UPDATE EMPLOYEE SET LNAME='YANG' WHERE EMP_ID=' VPA30890F'
这两个语句应该合并成以下一个语句
UPDATE EMPLOYEE SET FNAME='HAIWER',LNAME='YANG'WHERE EMP_ID=' VPA30890F'
E、UPDATE操作不要拆成DELETE操作+INSERT操作的形式,虽然功能相同,但是性能差别是很大的。
五、注意临时表和表变量的用
在复杂系统中,临时表和表变量很难避免,关于临时表和表变量的用法,需要注意:
A、如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成。
B、如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据。
C、如果需要综合多个表的数据,形成一个结果,可以考虑用临时表和表变量分步汇总这多个表的数据。
D、其他情况下,应该控制临时表和表变量的使用。
E、关于临时表和表变量的选择,很多说法是表变量在内存,速度快,应该首选表变量,但是在实际使用中发现:
(1) 主要考虑需要放在临时表的数据量,在数据量较多的情况下,临时表的速度反而更快。
(2) 执行时间段与预计执行时间(多长)
F、关于临时表产生使用SELECT INTO和CREATE TABLE + INSERT INTO的选择,一般情况下:
SELECT INTO会比CREATE TABLE + INSERT INTO的方法快很多,
但是SELECT INTO会锁定TEMPDB的系统表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,在多用户并发环境下,容易阻塞其他进程。
所以我的建议是,在并发系统中,尽量使用CREATE TABLE + INSERT INTO,而大数据量的单个语句使用中,使用SELECT INTO。
六、子查询的用法
子查询是一个 SELECT 查询,它嵌套在 SELECT、INSERT、UPDATE、DELETE 语句或其它子查询中。
任何允许使用表达式的地方都可以使用子查询,子查询可以使我们的编程灵活多样,可以用来实现一些特殊的功能。但是在性能上,往往一个不合适的子查询用法会形成一个性能瓶颈。如果子查询的条件中使用了其外层的表的字段,这种子查询就叫作相关子查询。
相关子查询可以用IN、NOT IN、EXISTS、NOT EXISTS引入。 关于相关子查询,应该注意:
(1) NOT IN、NOT EXISTS的相关子查询可以改用LEFT JOIN代替写法。比如:
SELECT PUB_NAME FROM PUBLISHERS WHERE PUB_ID NOTIN (SELECT PUB_ID FROM TITLES WHERE TYPE ='BUSINESS')
可以改写成:
SELECT A.PUB_NAME FROM PUBLISHERS A LEFTJOIN TITLES B ON B.TYPE ='BUSINESS'AND A.PUB_ID=B. PUB_ID WHERE B.PUB_ID IS NULL
比如NOT EXISTS:
SELECT TITLE FROM TITLES WHERE NOT EXISTS (SELECT TITLE_ID FROM SALES WHERE TITLE_ID = TITLES.TITLE_ID)
可以改写成:
SELECT TITLE FROM TITLES LEFTJOIN SALES ON SALES.TITLE_ID = TITLES.TITLE_ID WHERE SALES.TITLE_ID ISNULL
2)如果保证子查询没有重复 ,IN、EXISTS的相关子查询可以用INNER JOIN 代替。比如:
SELECT PUB_NAME FROM PUBLISHERS WHERE PUB_ID IN (SELECT PUB_ID FROM TITLES WHERE TYPE ='BUSINESS')
可以改写成:
SELECT A.PUB_NAME --SELECT DISTINCT A.PUB_NAME FROM PUBLISHERS A INNERJOIN TITLES B ON B.TYPE ='BUSINESS'AND A.PUB_ID=B. PUB_ID
(3) IN的相关子查询用EXISTS代替,比如:
SELECT PUB_NAME FROM PUBLISHERS WHERE PUB_ID IN (SELECT PUB_ID FROM TITLES WHERE TYPE ='BUSINESS')
可以用下面语句代替:
SELECT PUB_NAME FROM PUBLISHERS WHERE EXISTS (SELECT1FROM TITLES WHERE TYPE ='BUSINESS'AND PUB_ID= PUBLISHERS.PUB_ID)
4) 不要用COUNT(*)的子查询判断是否存在记录,最好用LEFT JOIN或者EXISTS,比如有人写这样的语句:
SELECT JOB_DESC FROM JOBS WHERE (SELECTCOUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)=0
应该改成:
SELECT JOBS.JOB_DESC FROM JOBS LEFTJOIN EMPLOYEE ON EMPLOYEE.JOB_ID=JOBS.JOB_ID WHERE EMPLOYEE.EMP_ID ISNULL SELECT JOB_DESC FROM JOBS WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)
应该改成:
SELECT JOB_DESC FROM JOBS WHEREEXISTS (SELECT 1 FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)
七:尽量使用索引
建立索引后,并不是每个查询都会使用索引,在使用索引的情况下,索引的使用效率也会有很大的差别。只要我们在查询语句中没有强制指定索引,索引的选择和使用方法是SQLSERVER的优化器自动作的选择,而它选择的根据是查询语句的条件以及相关表的统计信息,这就要求我们在写SQL语句的时候尽量使得优化器可以使用索引。为了使得优化器能高效使用索引,写语句的时候应该注意:
(1)不要对索引字段进行运算,而要想办法做变换,比如:
SELECT ID FROM T WHERE NUM/2=100
应改为:
SELECT ID FROM T WHERE NUM=100*2
SELECT ID FROM T WHERE NUM/2=NUM1
如果NUM有索引应改为:
SELECT ID FROM T WHERE NUM=NUM1*2
如果NUM1有索引则不应该改。
(2)发现过这样的语句:
SELECT 年,月,金额 FROM 结余表 WHERE100*年+月=2010*100+10
应该改为:
SELECT 年,月,金额 FROM 结余表 WHERE 年=2010 AND 月=10
(3)不要对索引字段进行格式转换
日期字段的例子:
WHERE CONVERT(VARCHAR(10), 日期字段,120)='2010-07-15'
应该改为
WHERE 日期字段〉='2010-07-15'AND 日期字段'2010-07-16'
ISNULL转换的例子:
WHERE ISNULL(字段,”)”应改为:WHERE字段”
WHERE ISNULL(字段,”)=”不应修改
WHERE ISNULL(字段,’F’) =’T’应改为: WHERE字段=’T’
WHERE ISNULL(字段,’F’)’T’不应修改
(4) 不要对索引字段进行格式转换
WHERE LEFT(NAME, 3)='ABC' 或者WHERE SUBSTRING(NAME,1, 3)='ABC'
应改为: WHERE NAME LIKE’ABC%’
日期查询的例子:
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-06-30' AND 日期 '2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期 '2010-06-30'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期 '2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-06-30'
(5)不要对索引字段使用函数
WHERE LEFT(NAME, 3)=’ABC’ 或者WHERE SUBSTRING(NAME,1, 3)=’ABC’
应改为:
WHERE NAME LIKE 'ABC%'
日期查询的例子:
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-06-30'AND 日期 '2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期 '2010-06-30'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期 '2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:
WHERE 日期='2010-06-30'
(6)不要对索引字段进行多字段连接
比如:
WHERE FAME+'. '+LNAME='HAIWEI.YANG'
应改为:
WHERE FNAME='HAIWEI' AND LNAME='YANG'
八:多表连接的连接条件对索引的选择有着重要的意义,所以我们在写连接条件条件的时候需要特别注意。
A、多表连接的时候,连接条件必须写全,宁可重复,不要缺漏。
B、连接条件尽量使用聚集索引
C、注意ON、WHERE和HAVING部分条件的区别
ON是最先执行, WHERE次之,HAVING最后,因为ON是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,WHERE也应该比HAVING快点的,因为它过滤数据后才进行SUM,在两个表联接时才用ON的,所以在一个表的时候,就剩下WHERE跟HAVING比较了。
(1) INNER JOIN
(2) LEFT JOIN (注:RIGHT JOIN 用 LEFT JOIN 替代)
(3) CROSS JOIN
其它注意和了解的地方有:
A、在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
B、注意UNION和UNION ALL的区别。– 允许重复数据用UNION ALL好
C、注意使用DISTINCT,在没有必要时不要用。
D、TRUNCATE TABLE 与 DELETE 区别。
E、减少访问数据库的次数。
还有就是我们写存储过程,如果比较长的话,最后用标记符标开,因为这样可读性很好,即使语句写的不怎么样,但是语句工整,C# 有region,SQL我比较喜欢用的就是:
–startof 查询在职人数
SQL语句
–end of
正式机器上我们一般不能随便调试程序,但是很多时候程序在我们本机上没问题,但是进正式系统就有问题,但是我们又不能随便在正式机器上操作,那么怎么办呢?我们可以用回滚来调试我们的存储过程或者是SQL语句,从而排错。
BEGINTRAN
UPDATE a SET 字段=”
ROLLBACK
作业存储过程我一般会加上下面这段,这样检查错误可以放在存储过程,如果执行错误回滚操作,但是如果程序里面已经有了事务回滚,那么存储过程就不要写事务了,这样会导致事务回滚嵌套降低执行效率,但是我们很多时候可以把检查放在存储过程里,这样有利于我们解读这个存储过程,和排错。
BEGINTRANSACTION
–事务回滚开始
–检查报错
IF ( @@ERROR0 )
BEGIN
--回滚操作
ROLLBACKTRANSACTION
RAISERROR('删除工作报告错误', 16, 3)
RETURN
END
–结束事务
COMMITTRANSACTION
Sparse Columns in SQL Server 2008
StandardSparse Column is one more new feature introduced in SQL SERVER 2008. Storing a null value in a sparse column doesn’t take any space, but storing a non-null value in sparse column takes 4 bytes extra space than the non-sparse columns of the same data type.
For example: As we know that storing a null/non-null value in a DATETIME column takes 8 bytes. On the other hand Sparse DATETIME column takes no space for storing null value but storing a non-null value will take 12 bytes i.e. 4 bytes extra then normal DATETIME column.
At this moment the obvious question which arises in our mind is: Why 0 bytes for null value and 4 bytes extra for storing non-null value in a sparse column? Reason for this is, sparse column’s value is not stored together with normal columns in a row, instead they are stored at the end of each row as special structure named Sparse Vector. Sparse vector structure contains:
[List of non-null Sparse Column Id’s – It takes 2 Bytes for each non-null Sparse column] + [List of Column Offsets — It takes 2 bytes for each non-null Sparse column].
So, defining columns with high density of null value as Sparse will result in huge space saving. As explained previously non-null value in the sparse column is stored in a complex structure, so reading non-null sparse column value will have slight performance overhead.
Let us understand the Sparse Column concept with below example.
Example: In this example we will create two identical tables. Only difference between them is, in one table two columns are marked as Sparse. In both of these tables insert some 25k records and check the space utilization by these tables.
CREATE DATABASE SPARSEDEMO GO USE SPARSEDEMO GO CREATE TABLE SPARSECOLUMNTABLE ( col1 int identity(1,1), col2 datetime sparse, col3 int sparse ) CREATE TABLE NONSPARSECOLUMNTABLE ( col1 int identity(1,1), col2 datetime, col3 int ) GO INSERT INTO SPARSECOLUMNTABLE VALUES(NULL,NULL) INSERT INTO NONSPARSECOLUMNTABLE VALUES(NULL,NULL) GO 25000
Now check the space used by these tables by executing the below statements:
EXEC SP_Spaceused SPARSECOLUMNTABLE EXEC SP_Spaceused NONSPARSECOLUMNTABLE
Result:
name rows reserved data index_size unused SPARSECOLUMNTABLE 25000 392 KB 344 KB 8 KB 40 KB name rows reserved data index_size unused NONSPARSECOLUMNTABLE 25000 712 KB 656 KB 8 KB 48 KB
So, with above example it is clear that defining a column with high density of null values result’s in huge space saving.
Exception Handling in Sql Server
StandardThis is the first article in the series of articles on Exception Handling in Sql Server. Below is the complete list of articles in this series.
Part I: Exception Handling Basics
Part II: TRY…CATCH (Introduced in Sql Server 2005)
Part III: RAISERROR Vs THROW (Throw: Introduced in Sql Server 2012)
Part IV: Exception Handling Template
Exception Handling Basics
If we are not clear about the basics of Exception handling in Sql Server, then it is the most complex/confusing task, it will become nightmarish job to identify the actual error and the root cause of the unexpected results. In this blog post I will try to make sure that all the concepts are cleared properly and the one who goes through it should feel the sense of something they have learnt new and feel themselves an expert in this area. And at the end of the blog post will present the ideal exception handling template which one should be using for proper error handling in Sql Server.
Last week on 11th January, 2014, I have presented a session on this topic at Microsoft Office in the Sql Bangalore User Group meeting which is attend by hundreds of enthusiastic Sql Server working professionals. Received very good feedback and few messages posted in the Facebook SQLBangalore user group were “Thanks Basavaraj Biradar! Your session was divine!” By Community Member Adarsh Prasad, “Thanks Basavaraj for your excellent session” By Community Member Selva Raj. Enough Self Praise, enough expectation is set, let’s cut short the long story short and move onto the deep dive of Exception handling basics
In this topic will cover the following concepts with extensive list of examples
- Error Message
- Error Actions
Error Message |
Let’s start with a simple statement like below which results in an exception as I am trying to access a non-existing table.
--------------Try To Access Non-Existing Table --------------- SELECT * FROM dbo.NonExistingTable GO |
Result of the above query:
Msg 208, Level 16, State 1, Line 2
Invalid object name ‘dbo.NonExistingTable’.
By looking at the above error message, we can see that the error message consists of following 5 parts:
Msg 208 – Error Number
Level 16 – Severity of the Error
State 1 – State of the Error
Line 2 – Line Number of the statement which generated the Error
Invalid object name ‘dbo.NonExistingTable’. – Actual Error Message
Now Let’s wrap the above statement which generated the error into a stored procedure as below
---Create the Stored Procedure CREATE PROCEDURE dbo.ErrorMessageDemoASBEGIN SELECT * FROM dbo.NonExistingTableENDGO--Execute the Stored ProcedureEXEC dbo.ErrorMessageDemoGO |
Result of executing the above stored procedure is:
Msg 208, Level 16, State 1, Procedure ErrorMessageDemo, Line 4
Invalid object name ‘dbo.NonExistingTable’.
If we compare this error message with the previous error message, then this message contains one extra part “Procedure ErrorMessageDemo“ specifying the name of the stored procedure in which the exception occurred.
Parts of ErrorMessage
The below image explains in detail each of the six parts of the error message which we have identified just above:
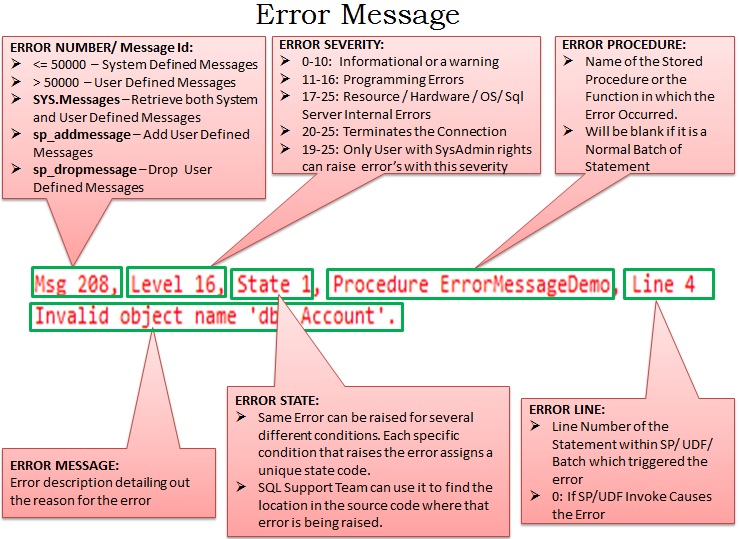
In case the image is not clear below is the detail which I have tried to present in it:
ERROR NUMBER/ Message Id:
Any error number which is <= 50000 is a System Defined Messages and the ones which are > 50000 are User Defined Messages. SYS.Messages catalog view can be used to retrieve both System and User Defined Messages. We can add a user defined message using sp_addmessage and we can remove it using the system stored procedure sp_dropmessage.
ERROR SEVERITY: Error Severity can be between 0-25.
0-10: Informational or a warning
11-16: Programming Errors
17-25: Resource / Hardware / OS/ Sql Server Internal Errors
20-25: Terminates the Connection
19-25: Only User with SysAdmin rights can raise error’s with this severity
ERROR STATE: Same Error can be raised for several different conditions in the code. Each specific condition that raises the error assigns a unique state code. Also the SQL Support Team uses it to find the location in the source code where that error is being raised.
ERROR PROCEDURE: Name of the Stored Procedure or the Function in which the Error Occurred. It Will be blank if it is a Normal Batch of Statement.
ERROR LINE: Line Number of the Statement within SP/ UDF/ Batch which triggered the error. It will be 0 If SP/UDF Invoke Causes the Error.
ERROR MESSAGE: Error description detailing out the reason for the error
Error Actions |
Now let us see how Sql Server Reacts to different errors. To demonstrate this let us create a New Database and table as shown below:
--Create a New database for the DemoCREATE DATABASE SqlHintsErrorHandlingDemoGOUSE SqlHintsErrorHandlingDemoGOCREATE TABLE dbo.Account( AccountId INT NOT NULL PRIMARY KEY, Name NVARCHAR (50) NOT NULL, Balance Money NOT NULL CHECK (Balance>=0) )GO |
As the Account table has Primary Key on the AccountId column, so it will raise an error if we try to duplicate the AccountId column value. And the Balance column has a CHECK constraint Balance>=0, so it will raise an exception if the value of Balance is <0.
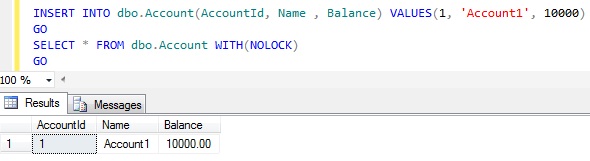
Let us first check whether we are able to insert valid Account into the Account table.
INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000) |
Result: We are able to successfully insert a record in the Account table
Now try to insert one more account whose AccountId is same as the one which we have just inserted above.
INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Duplicate', 10000) |
Result: It fails with below error message, because we are trying to insert a duplicate value for the the Primary Key column AccountId.
Msg 2627, Level 14, State 1, Line 1
Violation of PRIMARY KEY constraint ‘PK__Account__349DA5A67ED5FC72’. Cannot insert duplicate key in object ‘dbo.Account’. The duplicate key value is (1).
The statement has been terminated.
Let me empty the Account Table by using the below statement:
DELETE FROM dbo.Account |
DEMO 1: Now let us see what will be the result if we execute the below batch of Statements:
|
1
2
3
4
5
6
7
|
INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000)INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Duplicate', 10000)INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)GO |
Result: The First and Third Insert statements in the batch are succeeded even though the Second Insert statement fails
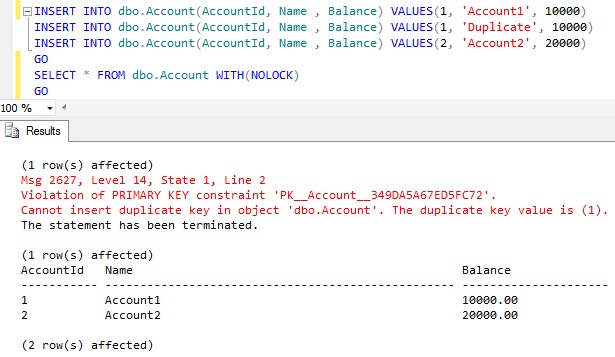
From the above example result it is clear that even though the Second insert statement is raising a primary key voilation error, Sql server continued the execution of the next statement and it has successfully inserted the Account with AccountId 2 by the third Insert statement.
If Sql Server terminates the statement which raised the error but continues to execute the next statements in the Batch. Then such a behavior by a Sql Server in response to an error is called Statement Termination.
Let me clear the Account Table by using the below statement before proceeding with the Next DEMO:
DELETE FROM dbo.Account |
DEMO 2: Now let us see what will be the result if we execute the below batch of Statements. The only difference between this batch of statement and the DEMO 1 is the first line i.e. SET XACT_ABORT ON:
|
1
2
3
4
5
6
7
8
|
SET XACT_ABORT ONINSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000)INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Duplicate', 10000)INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)GO |
RESULT: Only the first Insert succeeded
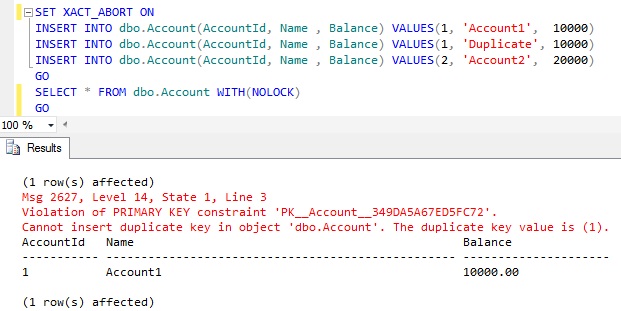
From the above example result it is clear that failure in the Second insert statement due to primary key violation caused Sql Server to terminate the execution of the Subsequent statements in the batch.
If Sql Server terminates the statement which raised the error and the subsequent statements in the batch then such behavior is termed as Batch Abortion.
The Only difference in the DEMO 2 script from DEMO 1 is the additional first statement SET XACT_ABORT ON. So from the result it is clear that the SET XACT_ABORT ON statement is causing Sql Server to do the Batch Abortion for a Statement Termination Error. It means SET XACT_ABORT ON converts the Statement Terminating errors to the Batch Abortion errors.
Let me clear the Account Table and also reset the Transaction Abort setting by using the below statement before proceeding with the Next DEMO :
DELETE FROM dbo.Account SET XACT_ABORT OFFGO |
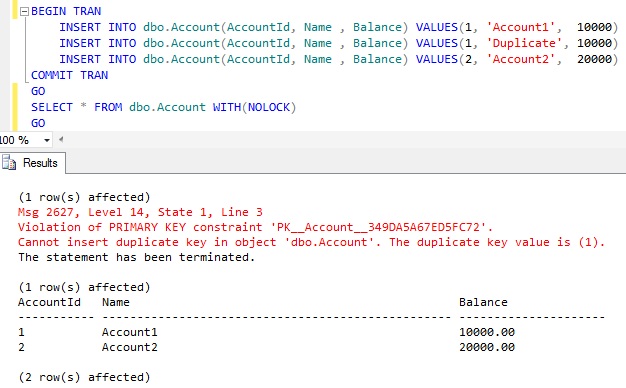
DEMO 3: Now let us see what will be the result if we execute the below batch of Statements. The only difference between this batch of statement and the DEMO 1 is that the INSERT statements are executed in a Transaction:
|
1
2
3
4
5
6
7
8
9
|
BEGIN TRAN INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000) INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Duplicate', 10000) INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)COMMIT TRANGO |
RESULT: Same as the DEMO 1, that is only the statement which raised the error is terminated but continues with the next statement in the batch. Here First and Third Inserts are Successful even though the Second statement raised the error.
Let me clear the Account Table by using the below statement before proceeding with the Next DEMO :
DELETE FROM dbo.AccountGO |
DEMO 4: Now let us see what will be the result if we execute the below batch of Statements. The only difference between this batch of statement and the DEMO 2 is that the INSERT statement’s are executed within a Transaction
|
1
2
3
4
5
6
7
8
9
10
|
SET XACT_ABORT ONBEGIN TRAN INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000) INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Duplicate', 10000) INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)COMMIT TRANGO |
RESULT: No records inserted
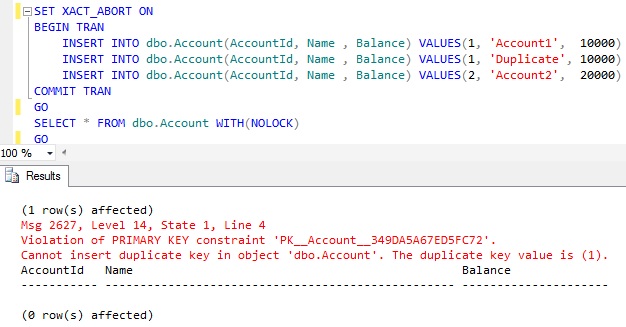
From the above example result it is clear that SET XACT_ABORT ON setting not only converts the Statement Termination Errors to the Batch Abortion Errors and also ROLLS BACK any active transactions started prior to the BATCH Abortion errors.
Let me clear the Account Table and also reset the Transaction Abort setting by using the below statement before proceeding with the Next DEMO :
DELETE FROM dbo.Account SET XACT_ABORT OFFGO |
DEMO 5: As a part of this DEMO we will verify what happens if a CONVERSION Error occurs within a batch of statement.
CONVERSION ERROR: Trying to convert the string ‘TEN THOUSAND’ to MONEY Type will result in an error. Let us see this with an example:
SELECT CAST('TEN THOUSAND' AS MONEY) |
RESULT:
Msg 235, Level 16, State 0, Line 1
Cannot convert a char value to money. The char value has incorrect syntax.
Now let us see what happens if we come across such a CONVERSION error within a batch of statement like the below one:
|
1
2
3
4
5
6
7
8
9
10
|
INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000)UPDATE dbo.Account SET Balance = Balance + CAST('TEN THOUSAND' AS MONEY) WHERE AccountId = 1INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)GO |
RESULT: Only the First INSERT is successful
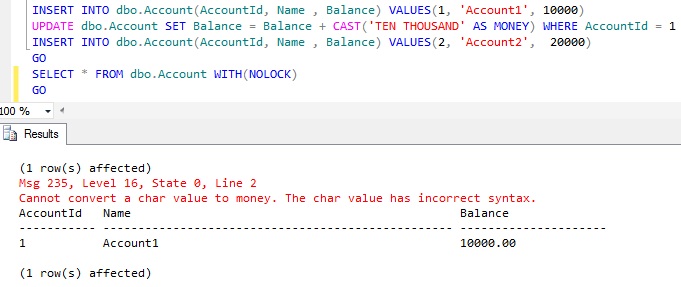
From the above result it is clear that CONVERSION errors cause the BATCH abortion, i.e Sql Server terminates the statement which raised the error and the subsequent statements in the batch. Where as PRIMARY KEY violation was resulting in a Statement Termination as explained in the DEMO 1.
Let me clear the Account Table by using the below statement before proceeding with the Next DEMO :
DELETE FROM dbo.AccountGO |
DEMO 6: Now let us see what will be the result if we execute the below batch of Statements. The only difference between this batch of statement and the previous DEMO 5 is that the Batch statement’s are executed within a Transaction
|
1
2
3
4
5
6
7
8
9
10
11
12
|
BEGIN TRAN INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(1, 'Account1', 10000) UPDATE dbo.Account SET Balance = Balance + CAST('TEN THOUSAND' AS MONEY) WHERE AccountId = 1 INSERT INTO dbo.Account(AccountId, Name , Balance) VALUES(2, 'Account2', 20000)COMMIT TRAN GO |
RESULT: No records inserted
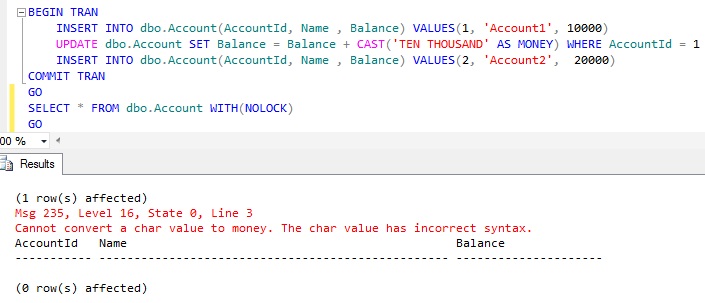
From the above example result it is clear that CONVERSION errors results in a BATCH Abortion and BATCH Abortion errors ROLLS BACK any active transactions started prior to the BATCH Abortion error.
Let me clear the Account Table and also reset the Transaction Abort setting by using the below statement before proceeding with the Next DEMO :
DELETE FROM dbo.Account SET XACT_ABORT OFFGO |
Enough examples, let me summarize the Sql Server Error Actions. Following are the four different ways Sql Server responds(i.e. Error Actions) in response to the errors:
- Statement Termination
- Scope Abortion
- Batch Abortion
- Connection Termination
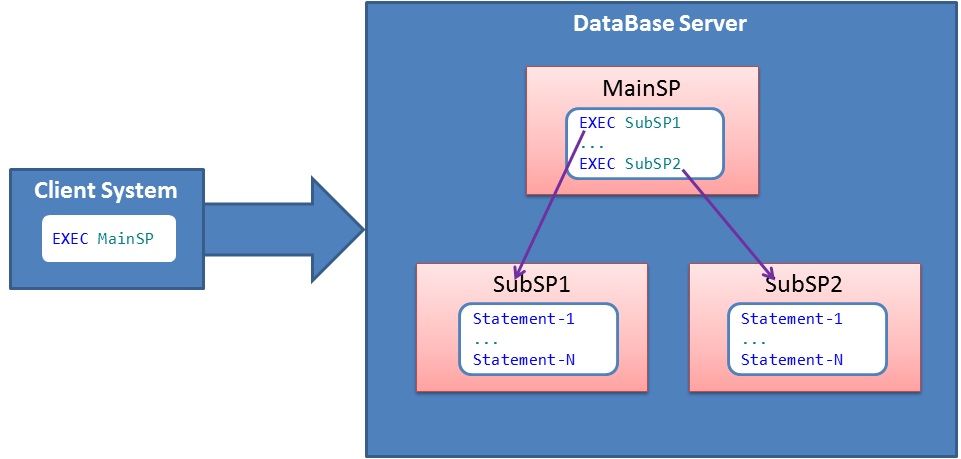
Many of these error actions I have explained in the above DEMOs using multiple examples. To explain these error actions further let us take a scenario as shown in the below image, in this scenario from client system an Execution request for the MainSP is submitted and the MainSP internally calls to sub sp’s SubSP1 and SubSP2 one after another:
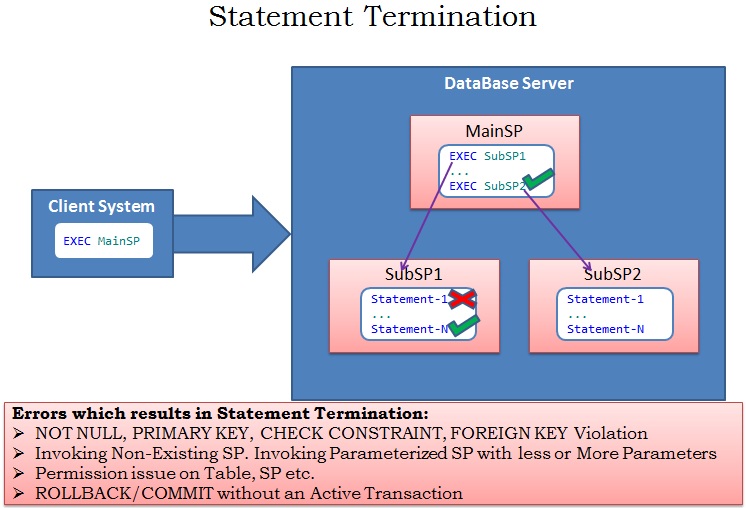
Statement Termination :
If Sql Server terminates the statement which raised the error but continues to execute the next statements in the Batch. Then such a behavior by a Sql Server in response to an error is called Statement Termination. As shown in the below image the Statement-1 in SubSP1 is causing an error, in response to this Sql Server terminates only the statement that raised the error i.e. Statement-1 but continues executing subsequent statements in the SubSP1 and MainSP calls the subsequent SP SubSp2.
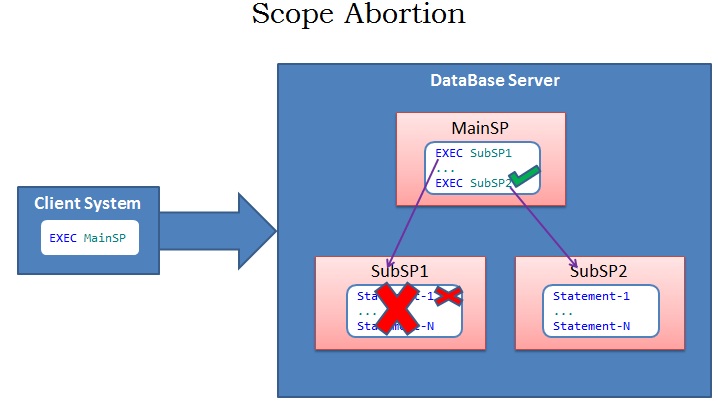
Scope Abortion :
If Sql Server terminates the statement which raised the error and the subsequent statements in the same scope, but continues to execute all the Statements outside the scope of the statement which raised the error. As shown in the below image the Statement-1 in SubSP1 is causing an error, in response to this Sql Server terminates not only the statement that raised the error i.e. Statement-1, but also terminates all the subsequent statements in the SubSP1, but continues executing further all the statements/Sub Sp’s (For Example SubSP2) in the MainSP.
Let us see this behavior with stored procedures similar to the one explained in the above image. Let us execute the below script to create the three stored procedures for this demo:
-------------Scope Abortion Demo--------------------Create SubSP1---------CREATE PROCEDURE dbo.SubSP1ASBEGIN PRINT 'Begining of SubSP1' --Try to access Non-Existent Table SELECT * FROM NonExistentTable PRINT 'End of SubSP1'ENDGO-------Create SubSP2---------CREATE PROCEDURE dbo.SubSP2ASBEGIN PRINT 'Inside SubSP2'ENDGO-------Create MainSP---------CREATE PROCEDURE dbo.MainSPASBEGIN PRINT 'Begining of MainSP' EXEC dbo.SubSP1 EXEC dbo.SubSP2 PRINT 'End of MainSP'ENDGO |
Once the above stored procedures are created, let us execute the MainSP by the below statement and verify the result:
EXEC dbo.MainSPGO |
RESULT:
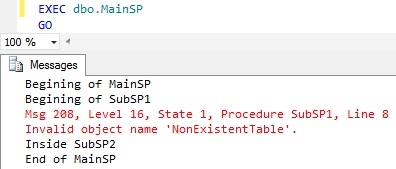
From the above SP execution results it is clear that the Access for a non existent table NonExistentTable from SubSP1 is not only terminating the statement which try’s to access this NonExistentTable table, but also the Subsequent statements in the SubSP1’s scope. But Sql Server continues with the execution of the subsequent statements which are present in the in the MainSP which has called this SubSP1 and also the SubSP2 is called from the MainSP.
Let us drop all the Stored Procedures created in this demo by using the below script:
DROP PROCEDURE dbo.SubSP2DROP PROCEDURE dbo.SubSP1DROP PROCEDURE dbo.MainSPGO |
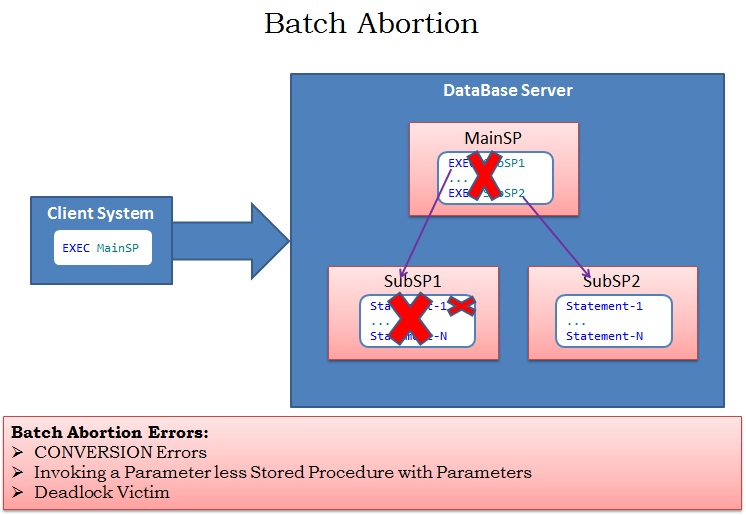
Batch Abortion :
If Sql Server terminates the statement which raised the error and the subsequent statements in the batch then such behavior is termed as Batch Abortion. As shown in the below image the Statement-1 in SubSP1 is causing an error, in response to this Sql Server terminates not only the statement that raised the error i.e. Statement-1, but also terminates all the subsequent statements in the SubSP1 and it will not execute the further statements/Sub Sp’s (For Example SubSP2) in the MainSP. Batch Abortion Errors ROLLS BACK any active transactions started prior to the statement which causes BATCH Abortion error.
We have already seen multiple Batch Abortion examples in the above DEMOs. Here let us see this behavior with stored procedures similar to the one explained in the above image. Let us execute the below script to create the three stored procedures for this demo:
------------Batch Abortion Demo ---------------------Create SubSP1---------CREATE PROCEDURE dbo.SubSP1ASBEGIN PRINT 'Begining of SubSP1' PRINT CAST('TEN THOUSAND' AS MONEY) PRINT 'End of SubSP1'ENDGO-------Create SubSP2---------CREATE PROCEDURE dbo.SubSP2ASBEGIN PRINT 'Inside SubSP2'ENDGO-------Create MainSP---------CREATE PROCEDURE dbo.MainSPASBEGIN PRINT 'Begining of MainSP ' EXEC dbo.SubSP1 EXEC dbo.SubSP2 PRINT 'End of MainSP 'ENDGO |
Once the above stored procedures are created, let us execute the MainSP by the below statement and verify the result:
EXEC dbo.MainSPGO |
RESULT:
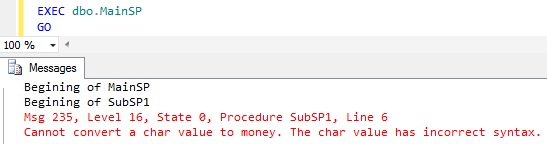
From the above SP execution results it is clear that the CONVERSION/CAST statement in the SubSP1 is causing the Batch Abortion.It is not only terminating the statement which raised the error but all the subsequent statement in the SubSP1 and the further statement in the MainSP which has called this SubSP1 and also the SubSP2 is not called from the MainSP post this error.
Let us drop all the Stored Procedures created in this demo by using the below script:
DROP PROCEDURE dbo.SubSP2DROP PROCEDURE dbo.SubSP1DROP PROCEDURE dbo.MainSPGO |
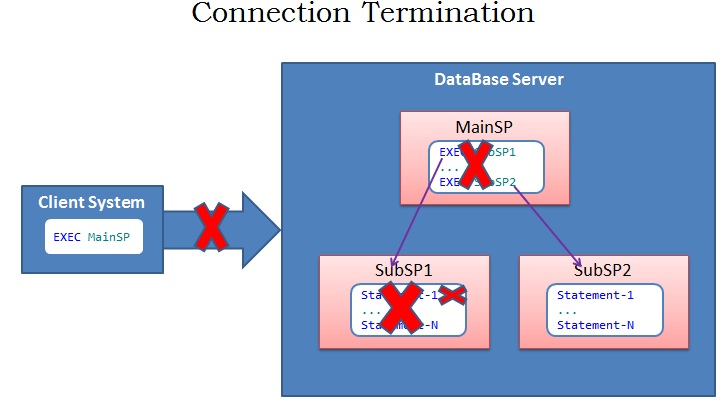
Connection Termination :
Errors with severity level 20-25 causes the Connection Termination. Only User with SysAdmin rights can raise error’s with these severity levels. As shown in the below image the Statement-1 in SubSP1 is causing an error with severity 20-25, in response to this Sql Server terminates not only the statement that raised the error i.e. Statement-1, but also terminates all the subsequent statements in the SubSP1 and it will not execute the further statements/Sub Sp’s (For Example SubSP2) in the MainSP. And finally terminates the connection. Note if there are any active Transactions which are started prior to the statement which caused the Connection Termination error, then Sql Server Takes care of Rolling Back all such transactions.
If we use RaiseError with WITH LOG option to raise an exception with severity level >=20 will result in a connection termination. Let us execute the below statement and observe the result:
RAISERROR('Connection Termination Error Demo', 20,1) WITH LOGGO |
RESULT: Connection is Terminated
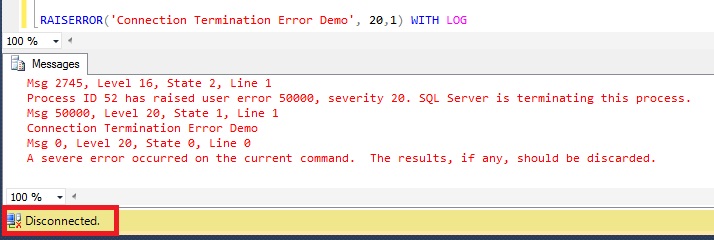
Below query gives the list of Error’s that cause the Connection Termination.
SELECT * FROM sys.messages WHERE severity >= 20 and language_id =1033 |
Clean-UP:
Let us drop the database which we have created for this demo
--Drop the Database SqlHintsErrorHandlingDemoUSE TempDBGODROP DATABASE SqlHintsErrorHandlingDemo |
Let us know your feedback on this post, hope you have learnt something new. Please correct me if there are any mistakes in this post, so that I can correct it and share with the community.
数据库性能优化之SQL语句优化
Standard一、问题的提出
在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的响应速度就成为目前系统需要解决的最主要的问题之一。系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统不是简单地能实现其功能就可,而是要写出高质量的SQL语句,提高系统的可用性。
在多数情况下,Oracle使用索引来更快地遍历表,优化器主要根据定义的索引来提高性能。但是,如果在SQL语句的where子句中写的SQL代码不合理,就会造成优化器删去索引而使用全表扫描,一般就这种SQL语句就是所谓的劣质SQL语句。在编写SQL语句时我们应清楚优化器根据何种原则来删除索引,这有助于写出高性能的SQL语句。
二、SQL语句编写注意问题
下面就某些SQL语句的where子句编写中需要注意的问题作详细介绍。在这些where子句中,即使某些列存在索引,但是由于编写了劣质的SQL,系统在运行该SQL语句时也不能使用该索引,而同样使用全表扫描,这就造成了响应速度的极大降低。
1. 操作符优化
(a) IN 操作符
用IN写出来的SQL的优点是比较容易写及清晰易懂,这比较适合现代软件开发的风格。但是用IN的SQL性能总是比较低的,从Oracle执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别:
ORACLE试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询。由此可见用IN的SQL至少多了一个转换的过程。一般的SQL都可以转换成功,但对于含有分组统计等方面的SQL就不能转换了。
推荐方案:在业务密集的SQL当中尽量不采用IN操作符,用EXISTS 方案代替。
(b) NOT IN操作符
此操作是强列不推荐使用的,因为它不能应用表的索引。
推荐方案:用NOT EXISTS 方案代替
(c) IS NULL 或IS NOT NULL操作(判断字段是否为空)
判断字段是否为空一般是不会应用索引的,因为索引是不索引空值的。不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
推荐方案:用其它相同功能的操作运算代替,如:a is not null 改为 a>0 或a>’’等。不允许字段为空,而用一个缺省值代替空值,如申请中状态字段不允许为空,缺省为申请。
(d) > 及 < 操作符(大于或小于操作符)
大于或小于操作符一般情况下是不用调整的,因为它有索引就会采用索引查找,但有的情况下可以对它进行优化,如一个表有100万记录,一个数值型字段A,30万记录的A=0,30万记录的A=1,39万记录的A=2,1万记录的A=3。那么执行A>2与A>=3的效果就有很大的区别了,因为A>2时ORACLE会先找出为2的记录索引再进行比较,而A>=3时ORACLE则直接找到=3的记录索引。
(e) LIKE操作符
LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题,如LIKE ‘%5400%’ 这种查询不会引用索引,而LIKE ‘X5400%’则会引用范围索引。
一个实际例子:用YW_YHJBQK表中营业编号后面的户标识号可来查询营业编号 YY_BH LIKE ‘%5400%’ 这个条件会产生全表扫描,如果改成YY_BH LIKE ’X5400%’ OR YY_BH LIKE ’B5400%’ 则会利用YY_BH的索引进行两个范围的查询,性能肯定大大提高。
带通配符(%)的like语句:
同样以上面的例子来看这种情况。目前的需求是这样的,要求在职工表中查询名字中包含cliton的人。可以采用如下的查询SQL语句:
select * from employee where last_name like '%cliton%';
这里由于通配符(%)在搜寻词首出现,所以Oracle系统不使用last_name的索引。在很多情况下可能无法避免这种情况,但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。在下面的查询中索引得到了使用:
select * from employee where last_name like 'c%';
(f) UNION操作符
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from gc_dfys union select * from ls_jg_dfys
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
推荐方案:采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
select * from gc_dfys union all select * from ls_jg_dfys
(g) 联接列
对于有联接的列,即使最后的联接值为一个静态值,优化器是不会使用索引的。我们一起来看一个例子,假定有一个职工表(employee),对于一个职工的姓和名分成两列存放(FIRST_NAME和LAST_NAME),现在要查询一个叫比尔.克林顿(Bill Cliton)的职工。
下面是一个采用联接查询的SQL语句:
select * from employss where first_name||''||last_name ='Beill Cliton';
上面这条语句完全可以查询出是否有Bill Cliton这个员工,但是这里需要注意,系统优化器对基于last_name创建的索引没有使用。当采用下面这种SQL语句的编写,Oracle系统就可以采用基于last_name创建的索引。
where first_name ='Beill' and last_name ='Cliton';
(h) Order by语句
ORDER BY语句决定了Oracle如何将返回的查询结果排序。Order by语句对要排序的列没有什么特别的限制,也可以将函数加入列中(象联接或者附加等)。任何在Order by语句的非索引项或者有计算表达式都将降低查询速度。
仔细检查order by语句以找出非索引项或者表达式,它们会降低性能。解决这个问题的办法就是重写order by语句以使用索引,也可以为所使用的列建立另外一个索引,同时应绝对避免在order by子句中使用表达式。
(i) NOT
我们在查询时经常在where子句使用一些逻辑表达式,如大于、小于、等于以及不等于等等,也可以使用and(与)、or(或)以及not(非)。NOT可用来对任何逻辑运算符号取反。下面是一个NOT子句的例子:
where not (status ='VALID')
如果要使用NOT,则应在取反的短语前面加上括号,并在短语前面加上NOT运算符。NOT运算符包含在另外一个逻辑运算符中,这就是不等于(<>)运算符。换句话说,即使不在查询where子句中显式地加入NOT词,NOT仍在运算符中,见下例:
where status <>'INVALID';
对这个查询,可以改写为不使用NOT:
select * from employee where salary<3000 or salary>3000;
虽然这两种查询的结果一样,但是第二种查询方案会比第一种查询方案更快些。第二种查询允许Oracle对salary列使用索引,而第一种查询则不能使用索引。
2. SQL书写的影响
(a) 同一功能同一性能不同写法SQL的影响。
如一个SQL在A程序员写的为 Select * from zl_yhjbqk
B程序员写的为 Select * from dlyx.zl_yhjbqk(带表所有者的前缀)
C程序员写的为 Select * from DLYX.ZLYHJBQK(大写表名)
D程序员写的为 Select * from DLYX.ZLYHJBQK(中间多了空格)
以上四个SQL在ORACLE分析整理之后产生的结果及执行的时间是一样的,但是从ORACLE共享内存SGA的原理,可以得出ORACLE对每个SQL 都会对其进行一次分析,并且占用共享内存,如果将SQL的字符串及格式写得完全相同,则ORACLE只会分析一次,共享内存也只会留下一次的分析结果,这不仅可以减少分析SQL的时间,而且可以减少共享内存重复的信息,ORACLE也可以准确统计SQL的执行频率。
(b) WHERE后面的条件顺序影响
WHERE子句后面的条件顺序对大数据量表的查询会产生直接的影响。如:
Select * from zl_yhjbqk where dy_dj = '1KV以下' and xh_bz=1 Select * from zl_yhjbqk where xh_bz=1 and dy_dj = '1KV以下'
以上两个SQL中dy_dj(电压等级)及xh_bz(销户标志)两个字段都没进行索引,所以执行的时候都是全表扫描,第一条SQL的dy_dj = ’1KV以下’条件在记录集内比率为99%,而xh_bz=1的比率只为0.5%,在进行第一条SQL的时候99%条记录都进行dy_dj及xh_bz的比较,而在进行第二条SQL的时候0.5%条记录都进行dy_dj及xh_bz的比较,以此可以得出第二条SQL的CPU占用率明显比第一条低。
(c) 查询表顺序的影响
在FROM后面的表中的列表顺序会对SQL执行性能影响,在没有索引及ORACLE没有对表进行统计分析的情况下,ORACLE会按表出现的顺序进行链接,由此可见表的顺序不对时会产生十分耗服物器资源的数据交叉。(注:如果对表进行了统计分析,ORACLE会自动先进小表的链接,再进行大表的链接)
3. SQL语句索引的利用
(a) 对条件字段的一些优化
采用函数处理的字段不能利用索引,如:
substr(hbs_bh,1,4)=’5400’,优化处理:hbs_bh like ‘5400%’ trunc(sk_rq)=trunc(sysdate), 优化处理:sk_rq>=trunc(sysdate) and sk_rq<trunc(sysdate+1)
进行了显式或隐式的运算的字段不能进行索引,如:ss_df+20>50,优化处理:ss_df>30
‘X’ || hbs_bh>’X5400021452’,优化处理:hbs_bh>’5400021542’ sk_rq+5=sysdate,优化处理:sk_rq=sysdate-5
hbs_bh=5401002554,优化处理:hbs_bh=’ 5401002554’,注:此条件对hbs_bh 进行隐式的to_number转换,因为hbs_bh字段是字符型。
条件内包括了多个本表的字段运算时不能进行索引,如:
ys_df>cx_df,无法进行优化 qc_bh || kh_bh=’5400250000’,优化处理:qc_bh=’5400’ and kh_bh=’250000’
4. 更多方面SQL优化资料分享
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效):
ORACLE 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
(2) WHERE子句中的连接顺序:
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
(3) SELECT子句中避免使用 ‘ * ‘:
ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间。
(4) 减少访问数据库的次数:
ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等。
(5) 在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200。
(6) 使用DECODE函数来减少处理时间:
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表.
(7) 整合简单,无关联的数据库访问:
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系) 。
(8) 删除重复记录:
最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO)。
(9) 用TRUNCATE替代DELETE:
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况) 而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短. (译者按: TRUNCATE只在删除全表适用,TRUNCATE是DDL不是DML) 。
(10) 尽量多使用COMMIT:
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少,COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
(11) 用Where子句替换HAVING子句:
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销. (非oracle中)on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where也应该比having快点的,因为它过滤数据后才进行sum,在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字 段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作 用的,所以在这种情况下,两者的结果会不同。在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表 后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
(12) 减少对表的查询:
在含有子查询的SQL语句中,要特别注意减少对表的查询.例子:
SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME,DB_VER) = ( SELECT TAB_NAME,DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
(13) 通过内部函数提高SQL效率:
复杂的SQL往往牺牲了执行效率. 能够掌握上面的运用函数解决问题的方法在实际工作中是非常有意义的。
(14) 使用表的别名(Alias):
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
(15) 用EXISTS替代IN、用NOT EXISTS替代NOT IN:
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接.在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率. 在子查询中,NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历). 为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS。
例子:
(高效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND EXISTS (SELECT ‘X' FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB') (低效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB')
(16) 识别’低效执行’的SQL语句:
虽然目前各种关于SQL优化的图形化工具层出不穷,但是写出自己的SQL工具来解决问题始终是一个最好的方法:
SELECT EXECUTIONS , DISK_READS, BUFFER_GETS, ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2) Hit_radio, ROUND(DISK_READS/EXECUTIONS,2) Reads_per_run, SQL_TEXT FROM V$SQLAREA WHERE EXECUTIONS>0 AND BUFFER_GETS > 0 AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8 ORDER BY 4 DESC;
(17) 用索引提高效率:
索引是表的一个概念部分,用来提高检索数据的效率,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证.。那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列. 通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率. 虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.。定期的重构索引是有必要的:
ALTER INDEX <INDEXNAME> REBUILD <TABLESPACENAME>
(18) 用EXISTS替换DISTINCT:
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换, EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果. 例子:
(低效): SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D , EMP E WHERE D.DEPT_NO = E.DEPT_NO (高效): SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE EXISTS ( SELECT ‘X' FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
(19) sql语句用大写的;因为oracle总是先解析sql语句,把小写的字母转换成大写的再执行。
(20) 在java代码中尽量少用连接符“+”连接字符串!
(21) 避免在索引列上使用NOT,通常我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的影响. 当ORACLE”遇到”NOT,他就会停止使用索引转而执行全表扫描。
(22) 避免在索引列上使用计算
WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.举例:
低效: SELECT … FROM DEPT WHERE SAL * 12 > 25000; 高效: SELECT … FROM DEPT WHERE SAL > 25000/12;
(23) 用>=替代>
高效: SELECT * FROM EMP WHERE DEPTNO >=4 低效: SELECT * FROM EMP WHERE DEPTNO >3
两者的区别在于, 前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录。
(24) 用UNION替换OR (适用于索引列)
通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低. 在下面的例子中, LOC_ID 和REGION上都建有索引.
高效: SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE LOC_ID = 10 UNION SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE REGION = “MELBOURNE” 低效: SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你坚持要用OR, 那就需要返回记录最少的索引列写在最前面.
(25) 用IN来替换OR
这是一条简单易记的规则,但是实际的执行效果还须检验,在ORACLE8i下,两者的执行路径似乎是相同的.
低效: SELECT…. FROM LOCATION WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30 高效 SELECT… FROM LOCATION WHERE LOC_IN IN (10,20,30);
(26) 避免在索引列上使用IS NULL和IS NOT NULL
避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引.对于单列索引,如果列包含空值,索引中将不存在此记录. 对于复合索引,如果每个列都为空,索引中同样不存在此记录. 如果至少有一个列不为空,则记录存在于索引中.举例: 如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入). 然而如果所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空. 因此你可以插入1000 条具有相同键值的记录,当然它们都是空! 因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引.
低效: (索引失效) SELECT … FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL; 高效: (索引有效) SELECT … FROM DEPARTMENT WHERE DEPT_CODE >=0;
(27) 总是使用索引的第一个列:
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 这也是一条简单而重要的规则,当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引。
(28) 用UNION-ALL 替换UNION ( 如果有可能的话):
当SQL 语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序. 如果用UNION ALL替代UNION, 这样排序就不是必要了. 效率就会因此得到提高. 需要注意的是,UNION ALL 将重复输出两个结果集合中相同记录. 因此各位还是要从业务需求分析使用UNION ALL的可行性. UNION 将对结果集合排序,这个操作会使用到SORT_AREA_SIZE这块内存. 对于这块内存的优化也是相当重要的. 下面的SQL可以用来查询排序的消耗量
低效: SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = '31-DEC-95' UNION SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = '31-DEC-95' 高效: SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = '31-DEC-95' UNION ALL SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = '31-DEC-95'
(29) 用WHERE替代ORDER BY:
ORDER BY 子句只在两种严格的条件下使用索引.
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中所有的列必须定义为非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列.
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL DEPT_DESC NOT NULL DEPT_TYPE NULL
低效: (索引不被使用) SELECT DEPT_CODE FROM DEPT ORDER BY DEPT_TYPE 高效: (使用索引) SELECT DEPT_CODE FROM DEPT WHERE DEPT_TYPE > 0
(30) 避免改变索引列的类型:
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.
假设 EMPNO是一个数值类型的索引列.
SELECT … FROM EMP WHERE EMPNO = ‘123'
实际上,经过ORACLE类型转换, 语句转化为:
SELECT … FROM EMP WHERE EMPNO = TO_NUMBER(‘123')
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变.
现在,假设EMP_TYPE是一个字符类型的索引列.
SELECT … FROM EMP WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT … FROM EMP WHERE TO_NUMBER(EMP_TYPE)=123
因为内部发生的类型转换, 这个索引将不会被用到! 为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来. 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型。
分析
select emp_name form employee where salary > 3000
在此语句中若salary是Float类型的,则优化器对其进行优化为Convert(float,3000),因为3000是个整数,我们应在编程时使用3000.0而不要等运行时让DBMS进行转化。同样字符和整型数据的转换。
(31) 需要当心的WHERE子句:
某些SELECT 语句中的WHERE子句不使用索引. 这里有一些例子.
在下面的例子里, (1)‘!=’ 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中. (2) ‘ ¦ ¦’是字符连接函数. 就象其他函数那样, 停用了索引. (3) ‘+’是数学函数. 就象其他数学函数那样, 停用了索引. (4)相同的索引列不能互相比较,这将会启用全表扫描.
(32) a. 如果检索数据量超过30%的表中记录数.使用索引将没有显著的效率提高. b. 在特定情况下, 使用索引也许会比全表扫描慢, 但这是同一个数量级上的区别. 而通常情况下,使用索引比全表扫描要块几倍乃至几千倍!
(33) 避免使用耗费资源的操作:
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序. 通常, 带有UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写. 如果你的数据库的SORT_AREA_SIZE调配得好, 使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强。
(34) 优化GROUP BY:
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多.
低效: SELECT JOB , AVG(SAL) FROM EMP GROUP by JOB HAVING JOB = ‘PRESIDENT' OR JOB = ‘MANAGER' 高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT' OR JOB = ‘MANAGER' GROUP by JOB
一小时学会C# 6
Standardc# 6已经出来有一段时间了,今天我们就详细地看一下这些新的特性。
一、字符串插值 (String Interpolation)
C# 6之前我们拼接字符串时需要这样
var Name = "Jack";
var results = "Hello" + Name;或者
var Name = "Jack";
var results = string.Format("Hello {0}", Name);但是C#6里我们就可以使用新的字符串插值特性
var Name = "Jack";
var results = $"Hello {Name}";上面只是一个简单的例子,想想如果有多个值要替换的话,用C#6的这个新特性,代码就会大大减小,而且可读性比起之前大大增强
Person p = new Person {FirstName = "Jack", LastName = "Wang", Age = 100};
var results = string.Format("First Name: {0} LastName: {1} Age: { 2} ", p.FirstName, p.LastName, p.Age);有了字符串插值后:
var results = $"First Name: {p.FirstName} LastName: {p.LastName} Age: {p.Age}";字符串插值不光是可以插简单的字符串,还可以直接插入代码
Console.WriteLine($"Jack is saying { new Tools().SayHello() }");
var info = $"Your discount is {await GetDiscount()}";那么如何处理多语言呢?
我们可以使用 IFormattable
下面的代码如何实现多语言?
Double remain = 2000.5;
var results= $"your money is {remain:C}";
# 输出 your money is $2,000.50使用IFormattable 多语言
class Program
{
static void Main(string[] args)
{
Double remain = 2000.5;
var results= ChineseText($"your money is {remain:C}");
Console.WriteLine(results);
Console.Read();
}
public static string ChineseText(IFormattable formattable)
{
return formattable.ToString(null, new CultureInfo("zh-cn"));
}
}
# 输出 your money is ¥2,000.50二、空操作符 ( ?. )
C# 6添加了一个 ?. 操作符,当一个对象或者属性职为空时直接返回null, 就不再继续执行后面的代码,在之前我们的代码里经常出现 NullException, 所以我们就需要加很多Null的判断,比如
if (user != null && user.Project != null && user.Project.Tasks != null && user.Project.Tasks.Count > 0)
{
Console.WriteLine(user.Project.Tasks.First().Name);
}现在我们可以不用写 IF 直接写成如下这样
Console.WriteLine(user?.Project?.Tasks?.First()?.Name);这个?. 特性不光是可以用于取值,也可以用于方法调用,如果对象为空将不进行任何操作,下面的代码不会报错,也不会有任何输出。
class Program
{
static void Main(string[] args)
{
User user = null;
user?.SayHello();
Console.Read();
}
}
public class User
{
public void SayHello()
{
Console.WriteLine("Ha Ha");
}
}还可以用于数组的索引器
class Program
{
static void Main(string[] args)
{
User[] users = null;
List<User> listUsers = null;
// Console.WriteLine(users[1]?.Name); // 报错
// Console.WriteLine(listUsers[1]?.Name); //报错
Console.WriteLine(users?[1].Name); // 正常
Console.WriteLine(listUsers?[1].Name); // 正常
Console.ReadLine();
}
}注意: 上面的代码虽然可以让我们少些很多代码,而且也减少了空异常,但是我们却需要小心使用,因为有的时候我们确实是需要抛出空异常,那么使用这个特性反而隐藏了Bug
三、 NameOf
过去,我们有很多的地方需要些硬字符串,导致重构比较困难,而且一旦敲错字母很难察觉出来,比如
if (role == "admin")
{
}WPF 也经常有这样的代码
public string Name
{
get { return name; }
set
{
name= value;
RaisePropertyChanged("Name");
}
}现在有了C#6 NameOf后,我们可以这样
public string Name
{
get { return name; }
set
{
name= value;
RaisePropertyChanged(NameOf(Name));
}
}
static void Main(string[] args)
{
Console.WriteLine(nameof(User.Name)); // output: Name
Console.WriteLine(nameof(System.Linq)); // output: Linq
Console.WriteLine(nameof(List<User>)); // output: List
Console.ReadLine();
}注意: NameOf只会返回Member的字符串,如果前面有对象或者命名空间,NameOf只会返回 . 的最后一部分, 另外NameOf有很多情况是不支持的,比如方法,关键字,对象的实例以及字符串和表达式
四、在Catch和Finally里使用Await
在之前的版本里,C#开发团队认为在Catch和Finally里使用Await是不可能,而现在他们在C#6里实现了它。
Resource res = null;
try
{
res = await Resource.OpenAsync(); // You could always do this.
}
catch (ResourceException e)
{
await Resource.LogAsync(res, e); // Now you can do this …
}
finally
{
if (res != null) await res.CloseAsync(); // … and this.
}五、表达式方法体
一句话的方法体可以直接写成箭头函数,而不再需要大括号
class Program
{
private static string SayHello() => "Hello World";
private static string JackSayHello() => $"Jack {SayHello()}";
static void Main(string[] args)
{
Console.WriteLine(SayHello());
Console.WriteLine(JackSayHello());
Console.ReadLine();
}
}六、自动属性初始化器
之前我们需要赋初始化值,一般需要这样
public class Person
{
public int Age { get; set; }
public Person()
{
Age = 100;
}
}但是C# 6的新特性里我们这样赋值
public class Person
{
public int Age { get; set; } = 100;
}七、只读自动属性
C# 1里我们可以这样实现只读属性
public class Person
{
private int age=100;
public int Age
{
get { return age; }
}
}但是当我们有自动属性时,我们没办法实行只读属性,因为自动属性不支持readonly关键字,所以我们只能缩小访问权限
public class Person
{
public int Age { get; private set; }
}但是 C#6里我们可以实现readonly的自动属性了
public class Person
{
public int Age { get; } = 100;
}八、异常过滤器 Exception Filter
static void Main(string[] args)
{
try
{
throw new ArgumentException("Age");
}
catch (ArgumentException argumentException) when( argumentException.Message.Equals("Name"))
{
throw new ArgumentException("Name Exception");
}
catch (ArgumentException argumentException) when( argumentException.Message.Equals("Age"))
{
throw new Exception("not handle");
}
catch (Exception e)
{
throw;
}
}在之前,一种异常只能被Catch一次,现在有了Filter后可以对相同的异常进行过滤,至于有什么用,那就是见仁见智了,我觉得上面的例子,定义两个具体的异常 NameArgumentException 和AgeArgumentException代码更易读。
九、 Index 初始化器
这个主要是用在Dictionary上,至于有什么用,我目前没感觉到有一点用处,谁能知道很好的使用场景,欢迎补充:
var names = new Dictionary<int, string>
{
[1] = "Jack",
[2] = "Alex",
[3] = "Eric",
[4] = "Jo"
};
foreach (var item in names)
{
Console.WriteLine($"{item.Key} = {item.Value}");
}十、using 静态类的方法可以使用 static using
这个功能在我看来,同样是很没有用的功能,也为去掉前缀有的时候我们不知道这个是来自哪里的,而且如果有一个同名方法不知道具体用哪个,当然经证实是使用类本身的覆盖,但是容易搞混不是吗?
using System;
using static System.Math;
namespace CSharp6NewFeatures
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(Log10(5)+PI);
}
}
}http://www.cnblogs.com/cnblogsfans/p/5086292.html
常用 Git 命令清单
Standard我每天使用 Git ,但是很多命令记不住。
一般来说,日常使用只要记住下图 6 个命令,就可以了。但是熟练使用,恐怕要记住 60~100 个命令。

下面是我整理的常用 Git 命令清单。几个专用名词的译名如下。
- Workspace:工作区
- Index / Stage:暂存区
- Repository:仓库区(或本地仓库)
- Remote:远程仓库
一、新建代码库
# 在当前目录新建一个 Git 代码库 $ git init # 新建一个目录,将其初始化为 Git 代码库 $ git init [project-name] # 下载一个项目和它的整个代码历史 $ git clone [url]
二、配置
Git 的设置文件为.gitconfig,它可以在用户主目录下(全局配置),也可以在项目目录下(项目配置)。
# 显示当前的 Git 配置 $ git config --list # 编辑 Git 配置文件 $ git config -e [--global] # 设置提交代码时的用户信息 $ git config [--global] user.name "[name]" $ git config [--global] user.email "[email address]"
三、增加/删除文件
# 添加指定文件到暂存区 $ git add [file1] [file2] ... # 添加指定目录到暂存区,包括子目录 $ git add [dir] # 添加当前目录的所有文件到暂存区 $ git add . # 删除工作区文件,并且将这次删除放入暂存区 $ git rm [file1] [file2] ... # 停止追踪指定文件,但该文件会保留在工作区 $ git rm --cached [file] # 改名文件,并且将这个改名放入暂存区 $ git mv [file-original] [file-renamed]
四、代码提交
# 提交暂存区到仓库区 $ git commit -m [message] # 提交暂存区的指定文件到仓库区 $ git commit [file1] [file2] ... -m [message] # 提交工作区自上次 commit 之后的变化,直接到仓库区 $ git commit -a # 提交时显示所有 diff 信息 $ git commit -v # 使用一次新的 commit,替代上一次提交 # 如果代码没有任何新变化,则用来改写上一次 commit 的提交信息 $ git commit --amend -m [message] # 重做上一次 commit,并包括指定文件的新变化 $ git commit --amend ...
五、分支
# 列出所有本地分支 $ git branch # 列出所有远程分支 $ git branch -r # 列出所有本地分支和远程分支 $ git branch -a # 新建一个分支,但依然停留在当前分支 $ git branch [branch-name] # 新建一个分支,并切换到该分支 $ git checkout -b [branch] # 新建一个分支,指向指定 commit $ git branch [branch] [commit] # 新建一个分支,与指定的远程分支建立追踪关系 $ git branch --track [branch] [remote-branch] # 切换到指定分支,并更新工作区 $ git checkout [branch-name] # 建立追踪关系,在现有分支与指定的远程分支之间 $ git branch --set-upstream [branch] [remote-branch] # 合并指定分支到当前分支 $ git merge [branch] # 选择一个 commit,合并进当前分支 $ git cherry-pick [commit] # 删除分支 $ git branch -d [branch-name] # 删除远程分支 $ git push origin --delete $ git branch -dr
六、标签
# 列出所有 tag $ git tag # 新建一个 tag 在当前 commit $ git tag [tag] # 新建一个 tag 在指定 commit $ git tag [tag] [commit] # 查看 tag 信息 $ git show [tag] # 提交指定 tag $ git push [remote] [tag] # 提交所有 tag $ git push [remote] --tags # 新建一个分支,指向某个 tag $ git checkout -b [branch] [tag]
七、查看信息
# 显示有变更的文件 $ git status # 显示当前分支的版本历史 $ git log # 显示 commit 历史,以及每次 commit 发生变更的文件 $ git log --stat # 显示某个文件的版本历史,包括文件改名 $ git log --follow [file] $ git whatchanged [file] # 显示指定文件相关的每一次 diff $ git log -p [file] # 显示指定文件是什么人在什么时间修改过 $ git blame [file] # 显示暂存区和工作区的差异 $ git diff # 显示暂存区和上一个 commit 的差异 $ git diff --cached [] # 显示工作区与当前分支最新 commit 之间的差异 $ git diff HEAD # 显示两次提交之间的差异 $ git diff [first-branch]...[second-branch] # 显示某次提交的元数据和内容变化 $ git show [commit] # 显示某次提交发生变化的文件 $ git show --name-only [commit] # 显示某次提交时,某个文件的内容 $ git show [commit]:[filename] # 显示当前分支的最近几次提交 $ git reflog
八、远程同步
# 下载远程仓库的所有变动 $ git fetch [remote] # 显示所有远程仓库 $ git remote -v # 显示某个远程仓库的信息 $ git remote show [remote] # 增加一个新的远程仓库,并命名 $ git remote add [shortname] [url] # 取回远程仓库的变化,并与本地分支合并 $ git pull [remote] [branch] # 上传本地指定分支到远程仓库 $ git push [remote] [branch] # 强行推送当前分支到远程仓库,即使有冲突 $ git push [remote] --force # 推送所有分支到远程仓库 $ git push [remote] --all
九、撤销
# 恢复暂存区的指定文件到工作区 $ git checkout [file] # 恢复某个 commit 的指定文件到工作区 $ git checkout [commit] [file] # 恢复上一个 commit 的所有文件到工作区 $ git checkout . # 重置暂存区的指定文件,与上一次 commit 保持一致,但工作区不变 $ git reset [file] # 重置暂存区与工作区,与上一次 commit 保持一致 $ git reset --hard # 重置当前分支的指针为指定 commit,同时重置暂存区,但工作区不变 $ git reset [commit] # 重置当前分支的 HEAD 为指定 commit,同时重置暂存区和工作区,与指定 commit 一致 $ git reset --hard [commit] # 重置当前 HEAD 为指定 commit,但保持暂存区和工作区不变 $ git reset --keep [commit] # 新建一个 commit,用来撤销指定 commit # 后者的所有变化都将被前者抵消,并且应用到当前分支 $ git revert [commit]
十、其他
# 生成一个可供发布的压缩包 $ git archive
Go语言错误处理
Standard近期闲暇用Go写一个lib,其中涉及到error处理的地方让我琢磨了许久。关于Go错误处理的资料和视频已有许多,Go authors们也在官方Articles和Blog上多次提到过一些Go error handling方面的一些tips和best practice,这里仅仅算是做个收集和小结,尽视野所及,如有不足,欢迎评论中补充。(10月因各种原因,没有耕博,月末来一发,希望未为晚矣 ^_^)
一、概述
Go是一门simple language,常拿出来鼓吹的就是作为gopher习以为傲的仅仅25个关键字^_^。因此Go的错误处理也一如既往的简单。我们知道C语言错误处理以返 回错误码(errno)为主流,目前企业第一语言Java则用try-catch- finally的处理方式来统一应对错误和异常(开发人员常常因分不清楚到底哪些是错误,哪些是异常而滥用该机制)。Go则继承了C,以返回值为错误处理的主要方式(辅以panic与recover应对runtime异常)。但与C不同的是,在Go的惯用法中,返回值不是整型等常用返回值类型,而是用了一个 error(interface类型)。
type interface error {
Error() string
}
这也体现了Go哲学中的“正交”理念:error context与error类型的分离。无论error context是int、float还是string或是其他,统统用error作为返回值类型即可。
func yourFunction(parametersList) (..., error)
func (Receiver)yourMethod(parametersList) (..., error)
在Andrew Gerrand的“Error handling and Go“一文中,这位Go authors之一明确了error context是由error接口实现者supply的。在Go标准库中,Go提供了两种创建一个实现了error interface的类型的变量实例的方法:errors.New和fmt.Errorf:
errors.New("your first error code")
fmt.Errorf("error value is %d\n", errcode)
这两个方法实际上返回的是同一个实现了error interface的类型实例,这个unexported类型就是errorString。顾名思义,这个error type仅提供了一个string的context!
//$GOROOT/srcerrors/errors.go
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
这两个方法也基本满足了大部分日常学习和开发中代码中的错误处理需求。
二、惯用法(idiomatic usage)
1、基本用法
就像上面函数或方法定义那样:
func yourFunction(parametersList) (..., error)
func (Receiver)yourMethod(parametersList) (..., error)
通常情况,我们将函数或方法定义中的最后一个返回值类型定义为error。使用该函数或方法时,通过如下方式判断错误码:
..., err := yourFunction(...)
if err != nil {
//error handling
}
or
if ..., err := yourFunction(...); err != nil {
//error handling
}
2、注意事项
1)、永远不要忽略(ignore)函数或方法返回的错误码,Check it。(例外:包括标准库在内的Go代码很少去判断fmt.Println or Printf系列函数的返回值)
2)、error的string context中的内容格式:头母小写,结尾不带标点。因为考虑到error被经常这么用:
... err := errors.New("error example")
fmt.Printf("The returned error is %s.\n", err)
3)、error处理流的缩进样式
prefer
..., err := yourFunction(...)
if err != nil {
// handle error
}
//go on doing something.
rather than:
..., err := yourFunction(...)
if err == nil {
// do something.
}
// handle error
三、槽点与破解之法
Go自诞生那天起就伴随着巨大争议,这也不奇怪,就像娱乐圈,如果没有争议,哪有存在感,刷脸的机会都没有。看来有争议是件好事,没争议的编程语言都已经成为了历史。炒作懂么!这也是很多Gopher的微博、微信、twitter、medium账号喜欢发“Why I do not like Go”类文章的原因吧^_^。
Go的error处理方式就是被诟病的点之一,反方主要论点就是Go的错误处理机制似乎回到了70年代(与C同龄^_^),使得错误处理代码冗长且重复(部分也是由于前面提到的:不要ignore任何一个错误码),比如一些常见的错误处理代码形式如下:
err := doStuff1()
if err != nil {
//handle error...
}
err = doStuff2()
if err != nil {
//handle error...
}
err = doStuff3()
if err != nil {
//handle error...
}
这里不想去反驳这些论点,Go authors之一的Russ Cox对于这种观点进行过驳斥:当初选择返回值这种错误处理机制而不是try-catch这种机制,主要是考虑前者适用于大型软件,后者更适合小程序。当程序变大,try-catch会让错误处理更加冗长繁琐易出错(具体参见go faq)。不过Russ Cox也承认Go的错误处理机制对于开发人员的确有一定的心智负担。
好了,关于这个槽点的叙述点到为止,我们关心的是“如何破解”!Go的错误处理的确冗长,但使用一些tips,还是可以将代码缩减至可以忍受的范围的,这里列举三种:
1、checkError style
对于一些在error handle时可以选择goroutine exit(注意:如果仅存main goroutine一个goroutine,调用runtime.Goexit会导致program以crash形式退出)或os.Exit的情形,我们可以选择类似常见的checkError方式简化错误处理,例如:
func checkError(err error) {
if err != nil {
fmt.Println("Error is ", err)
os.Exit(-1)
}
}
func foo() {
err := doStuff1()
checkError(err)
err = doStuff2()
checkError(err)
err = doStuff3()
checkError(err)
}
这种方式有些类似于C中用宏(macro)简化错误处理过程代码,只是由于Go不支持宏,使得这种方式的应用范围有限。
2、聚合error handle functions
有些时候,我们会遇到这样的情况:
err := doStuff1()
if err != nil {
//handle A
//handle B
... ...
}
err = doStuff2()
if err != nil {
//handle A
//handle B
... ...
}
err = doStuff3()
if err != nil {
//handle A
//handle B
... ...
}
在每个错误处理过程,处理过程相似,都是handle A、handle B等,我们可以通过Go提供的defer + 闭包的方式,将handle A、handle B…聚合到一个defer匿名helper function中去:
func handleA() {
fmt.Println("handle A")
}
func handleB() {
fmt.Println("handle B")
}
func foo() {
var err error
defer func() {
if err != nil {
handleA()
handleB()
}
}()
err = doStuff1()
if err != nil {
return
}
err = doStuff2()
if err != nil {
return
}
err = doStuff3()
if err != nil {
return
}
}
3、 将doStuff和error处理绑定
在Rob Pike的”Errors are values”一文中,Rob Pike told us 标准库中使用了一种简化错误处理代码的trick,bufio的Writer就使用了这个trick:
b := bufio.NewWriter(fd)
b.Write(p0[a:b])
b.Write(p1[c:d])
b.Write(p2[e:f])
// and so on
if b.Flush() != nil {
return b.Flush()
}
}
我们看到代码中并没有判断三个b.Write的返回错误值,错误处理放在哪里了呢?我们打开一下$GOROOT/src/
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
func (b *Writer) Write(p []byte) (nn int, err error) {
for len(p) > b.Available() && b.err == nil {
... ...
}
if b.err != nil {
return nn, b.err
}
......
return nn, nil
}
我们可以看到,错误处理被绑定在Writer.Write的内部了,Writer定义中有一个err作为一个错误状态值,与Writer的实例绑定在了一起,并且在每次Write入口判断是否为!= nil。一旦!=nil,Write其实什么都没做就return了。
以上三种破解之法,各有各的适用场景,同样你也可以看出各有各的不足,没有普适之法。优化go错误处理之法也不会局限在上述三种情况,肯定会有更多的solution,比如代码生成,比如其他还待发掘。
四、解调用者之惑
前面举的例子对于调用者来讲都是较为简单的情况了。但实际编码中,调用者不仅要面对的是:
if err != nil {
//handle error
}
还要面对:
if err 是 ErrXXX
//handle errorXXX
if err 是 ErrYYY
//handle errorYYY
if err 是ErrZZZ
//handle errorZZZ
我们分三种情况来说明调用者该如何处理不同类型的error实现:
1、由errors.New或fmt.Errorf返回的错误变量
如果你调用的函数或方法返回的错误变量是调用errors.New或fmt.Errorf而创建的,由于errorString类型是unexported的,因此我们无法通过“相当判定”或type assertion、type switch来区分不同错误变量的值或类型,唯一的方法就是判断err.String()是否与某个错误context string相等,示意代码如下:
func openFile(name string) error {
if file not exist {
return errors.New("file does not exist")
}
if have no priviledge {
return errors.New("no priviledge")
}
return nil
}
func main() {
err := openFile("example.go")
if err.Error() == "file does not exist" {
// handle "file does not exist" error
return
}
if err.Error() == "no priviledge" {
// handle "no priviledge" error
return
}
}
但这种情况太low了,不建议这么做!一旦遇到类似情况,就要考虑通过下面方法对上述情况进行重构。
2、exported Error变量
打开$GOROOT/src/os/error.go,你会在文件开始处发现如下代码:
var (
ErrInvalid = errors.New("invalid argument")
ErrPermission = errors.New("permission denied")
ErrExist = errors.New("file already exists")
ErrNotExist = errors.New("file does not exist")
)
这些就是os包export的错误码变量,由于是exported的,我们在调用os包函数返回后判断错误码时可以直接使用等于判定,比如:
err := os.XXX
if err == os.ErrInvalid {
//handle invalid
}
... ...
也可以使用switch case:
switch err := os.XXX {
case ErrInvalid:
//handle invalid
case ErrPermission:
//handle no permission
... ...
}
... ...
(至于error类型变量与os.ErrInvalid的可比较性可参考go specs。
一般对于库的设计和实现者而言,在库的设计时就要考虑好export出哪些错误变量。
3、定义自己的error接口实现类型
如果要提供额外的error context,我们可以定义自己的实现error接口的类型;如果这些类型还是exported的,我们就可以用type assertion or type switch来判断返回的错误码类型并予以对应处理。
比如$GOROOT/src/net/net.go:
type OpError struct {
Op string
Net string
Source Addr
Addr Addr
Err error
}
func (e *OpError) Error() string {
if e == nil {
return "<nil>"
}
s := e.Op
if e.Net != "" {
s += " " + e.Net
}
if e.Source != nil {
s += " " + e.Source.String()
}
if e.Addr != nil {
if e.Source != nil {
s += "->"
} else {
s += " "
}
s += e.Addr.String()
}
s += ": " + e.Err.Error()
return s
}
net.OpError提供了丰富的error Context,不仅如此,它还实现了除Error以外的其他method,比如:Timeout(实现net.timeout interface) 和Temporary(实现net.temporary interface)。这样我们在处理error时,可通过type assertion或type switch将error转换为*net.OpError,并调用到Timeout或Temporary方法来实现一些特殊的判定。
err := net.XXX
if oe, ok := err.(*OpError); ok {
if oe.Timeout() {
//handle timeout...
}
}
五、坑(s)
每种编程语言都有自己的专属坑(s),Go虽出身名门,但毕竟年轻,坑也不少,在error处理这块也可以列出几个。
1、 Go FAQ:Why is my nil error value not equal to nil?
type MyError string
func (e *MyError) Error() string {
return string(*e)
}
var ErrBad = MyError("ErrBad")
func bad() bool {
return false
}
func returnsError() error {
var p *MyError = nil
if bad() {
p = &ErrBad
}
return p // Will always return a non-nil error.
}
func main() {
err := returnsError()
if err != nil {
fmt.Println("return non-nil error")
return
}
fmt.Println("return nil")
}
上面的输出结果是”return non-nil error”,也就是说returnsError返回后,err != nil。err是一个interface类型变量,其underlying有两部分组成:类型和值。只有这两部分都为nil时,err才为nil。但returnsError返回时将一个值为nil,但类型为*MyError的变量赋值为err,这样err就不为nil。解决方法:
func returnsError() error {
var p *MyError = nil
if bad() {
p = &ErrBad
return p
}
return nil
}
2、switch err.(type)的匹配次序
试想一下下面代码的输出结果:
type MyError string
func (e MyError) Error() string {
return string(e)
}
func Foo() error {
return MyError("foo error")
}
func main() {
err := Foo()
switch e := err.(type) {
default:
fmt.Println("default")
case error:
fmt.Println("found an error:", e)
case MyError:
fmt.Println("found MyError:", e)
}
return
}
你可能会以为会输出:”found MyError: foo error”,但实际输出却是:”found an error: foo error”,也就是说e先匹配到了error!如果我们调换一下次序呢:
... ...
func main() {
err := Foo()
switch e := err.(type) {
default:
fmt.Println("default")
case MyError:
fmt.Println("found MyError:", e)
case error:
fmt.Println("found an error:", e)
}
return
}
这回输出结果变成了:“found MyError: foo error”。
也许你会认为这不全是错误处理的坑,和switch case的匹配顺序有关,但不可否认的是有些人会这么去写代码,一旦这么写,坑就踩到了。因此对于通过switch case来判定error type的情况,将error这个“通用”类型放在后面或去掉。
六、第三方库
如果觉得go内置的错误机制不能很好的满足你的需求,本着“do not reinvent the wheel”的精神,建议使用一些第三方库来满足,比如:juju/errors。这里就不赘述了。
Go语言TCP Socket编程
StandardGolang的主要 设计目标之一就是面向大规模后端服务程序,网络通信这块是服务端 程序必不可少也是至关重要的一部分。在日常应用中,我们也可以看到Go中的net以及其subdirectories下的包均是“高频+刚需”,而TCP socket则是网络编程的主流,即便您没有直接使用到net中有关TCP Socket方面的接口,但net/http总是用到了吧,http底层依旧是用tcp socket实现的。
网络编程方面,我们最常用的就是tcp socket编程了,在posix标准出来后,socket在各大主流OS平台上都得到了很好的支持。关于tcp programming,最好的资料莫过于W. Richard Stevens 的网络编程圣经《UNIX网络 编程 卷1:套接字联网API》 了,书中关于tcp socket接口的各种使用、行为模式、异常处理讲解的十分细致。Go是自带runtime的跨平台编程语言,Go中暴露给语言使用者的tcp socket api是建立OS原生tcp socket接口之上的。由于Go runtime调度的需要,golang tcp socket接口在行为特点与异常处理方面与OS原生接口有着一些差别。这篇博文的目标就是整理出关于Go tcp socket在各个场景下的使用方法、行为特点以及注意事项。
一、模型
从tcp socket诞生后,网络编程架构模型也几经演化,大致是:“每进程一个连接” –> “每线程一个连接” –> “Non-Block + I/O多路复用(linux epoll/windows iocp/freebsd darwin kqueue/solaris Event Port)”。伴随着模型的演化,服务程序愈加强大,可以支持更多的连接,获得更好的处理性能。
目前主流web server一般均采用的都是”Non-Block + I/O多路复用”(有的也结合了多线程、多进程)。不过I/O多路复用也给使用者带来了不小的复杂度,以至于后续出现了许多高性能的I/O多路复用框架, 比如libevent、libev、libuv等,以帮助开发者简化开发复杂性,降低心智负担。不过Go的设计者似乎认为I/O多路复用的这种通过回调机制割裂控制流 的方式依旧复杂,且有悖于“一般逻辑”设计,为此Go语言将该“复杂性”隐藏在Runtime中了:Go开发者无需关注socket是否是 non-block的,也无需亲自注册文件描述符的回调,只需在每个连接对应的goroutine中以“block I/O”的方式对待socket处理即可,这可以说大大降低了开发人员的心智负担。一个典型的Go server端程序大致如下:
//go-tcpsock/server.go
func handleConn(c net.Conn) {
defer c.Close()
for {
// read from the connection
// ... ...
// write to the connection
//... ...
}
}
func main() {
l, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println("listen error:", err)
return
}
for {
c, err := l.Accept()
if err != nil {
fmt.Println("accept error:", err)
break
}
// start a new goroutine to handle
// the new connection.
go handleConn(c)
}
}
用户层眼中看到的goroutine中的“block socket”,实际上是通过Go runtime中的netpoller通过Non-block socket + I/O多路复用机制“模拟”出来的,真实的underlying socket实际上是non-block的,只是runtime拦截了底层socket系统调用的错误码,并通过netpoller和goroutine 调度让goroutine“阻塞”在用户层得到的Socket fd上。比如:当用户层针对某个socket fd发起read操作时,如果该socket fd中尚无数据,那么runtime会将该socket fd加入到netpoller中监听,同时对应的goroutine被挂起,直到runtime收到socket fd 数据ready的通知,runtime才会重新唤醒等待在该socket fd上准备read的那个Goroutine。而这个过程从Goroutine的视角来看,就像是read操作一直block在那个socket fd上似的。具体实现细节在后续场景中会有补充描述。
二、TCP连接的建立
众所周知,TCP Socket的连接的建立需要经历客户端和服务端的三次握手的过程。连接建立过程中,服务端是一个标准的Listen + Accept的结构(可参考上面的代码),而在客户端Go语言使用net.Dial或DialTimeout进行连接建立:
阻塞Dial:
conn, err := net.Dial("tcp", "google.com:80")
if err != nil {
//handle error
}
// read or write on conn
或是带上超时机制的Dial:
conn, err := net.DialTimeout("tcp", ":8080", 2 * time.Second)
if err != nil {
//handle error
}
// read or write on conn
对于客户端而言,连接的建立会遇到如下几种情形:
1、网络不可达或对方服务未启动
如果传给Dial的Addr是可以立即判断出网络不可达,或者Addr中端口对应的服务没有启动,端口未被监听,Dial会几乎立即返回错误,比如:
//go-tcpsock/conn_establish/client1.go
... ...
func main() {
log.Println("begin dial...")
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Println("dial error:", err)
return
}
defer conn.Close()
log.Println("dial ok")
}
如果本机8888端口未有服务程序监听,那么执行上面程序,Dial会很快返回错误:
$go run client1.go
2015/11/16 14:37:41 begin dial...
2015/11/16 14:37:41 dial error: dial tcp :8888: getsockopt: connection refused
2、对方服务的listen backlog满
还有一种场景就是对方服务器很忙,瞬间有大量client端连接尝试向server建立,server端的listen backlog队列满,server accept不及时((即便不accept,那么在backlog数量范畴里面,connect都会是成功的,因为new conn已经加入到server side的listen queue中了,accept只是从queue中取出一个conn而已),这将导致client端Dial阻塞。我们还是通过例子感受Dial的行为特点:
服务端代码:
//go-tcpsock/conn_establish/server2.go
... ...
func main() {
l, err := net.Listen("tcp", ":8888")
if err != nil {
log.Println("error listen:", err)
return
}
defer l.Close()
log.Println("listen ok")
var i int
for {
time.Sleep(time.Second * 10)
if _, err := l.Accept(); err != nil {
log.Println("accept error:", err)
break
}
i++
log.Printf("%d: accept a new connection\n", i)
}
}
客户端代码:
//go-tcpsock/conn_establish/client2.go
... ...
func establishConn(i int) net.Conn {
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Printf("%d: dial error: %s", i, err)
return nil
}
log.Println(i, ":connect to server ok")
return conn
}
func main() {
var sl []net.Conn
for i := 1; i < 1000; i++ {
conn := establishConn(i)
if conn != nil {
sl = append(sl, conn)
}
}
time.Sleep(time.Second * 10000)
}
从程序可以看出,服务端在listen成功后,每隔10s钟accept一次。客户端则是串行的尝试建立连接。这两个程序在Darwin下的执行 结果:
$go run server2.go
2015/11/16 21:55:41 listen ok
2015/11/16 21:55:51 1: accept a new connection
2015/11/16 21:56:01 2: accept a new connection
... ...
$go run client2.go
2015/11/16 21:55:44 1 :connect to server ok
2015/11/16 21:55:44 2 :connect to server ok
2015/11/16 21:55:44 3 :connect to server ok
... ...
2015/11/16 21:55:44 126 :connect to server ok
2015/11/16 21:55:44 127 :connect to server ok
2015/11/16 21:55:44 128 :connect to server ok
2015/11/16 21:55:52 129 :connect to server ok
2015/11/16 21:56:03 130 :connect to server ok
2015/11/16 21:56:14 131 :connect to server ok
... ...
可以看出Client初始时成功地一次性建立了128个连接,然后后续每阻塞近10s才能成功建立一条连接。也就是说在server端 backlog满时(未及时accept),客户端将阻塞在Dial上,直到server端进行一次accept。至于为什么是128,这与darwin 下的默认设置有关:
$sysctl -a|grep kern.ipc.somaxconn
kern.ipc.somaxconn: 128
如果我在ubuntu 14.04上运行上述server程序,我们的client端初始可以成功建立499条连接。
如果server一直不accept,client端会一直阻塞么?我们去掉accept后的结果是:在Darwin下,client端会阻塞大 约1分多钟才会返回timeout:
2015/11/16 22:03:31 128 :connect to server ok
2015/11/16 22:04:48 129: dial error: dial tcp :8888: getsockopt: operation timed out
而如果server运行在ubuntu 14.04上,client似乎一直阻塞,我等了10多分钟依旧没有返回。 阻塞与否看来与server端的网络实现和设置有关。
3、网络延迟较大,Dial阻塞并超时
如果网络延迟较大,TCP握手过程将更加艰难坎坷(各种丢包),时间消耗的自然也会更长。Dial这时会阻塞,如果长时间依旧无法建立连接,则Dial也会返回“ getsockopt: operation timed out”错误。
在连接建立阶段,多数情况下,Dial是可以满足需求的,即便阻塞一小会儿。但对于某些程序而言,需要有严格的连接时间限定,如果一定时间内没能成功建立连接,程序可能会需要执行一段“异常”处理逻辑,为此我们就需要DialTimeout了。下面的例子将Dial的最长阻塞时间限制在2s内,超出这个时长,Dial将返回timeout error:
//go-tcpsock/conn_establish/client3.go
... ...
func main() {
log.Println("begin dial...")
conn, err := net.DialTimeout("tcp", "104.236.176.96:80", 2*time.Second)
if err != nil {
log.Println("dial error:", err)
return
}
defer conn.Close()
log.Println("dial ok")
}
执行结果如下(需要模拟一个延迟较大的网络环境):
$go run client3.go
2015/11/17 09:28:34 begin dial...
2015/11/17 09:28:36 dial error: dial tcp 104.236.176.96:80: i/o timeout
三、Socket读写
连接建立起来后,我们就要在conn上进行读写,以完成业务逻辑。前面说过Go runtime隐藏了I/O多路复用的复杂性。语言使用者只需采用goroutine+Block I/O的模式即可满足大部分场景需求。Dial成功后,方法返回一个net.Conn接口类型变量值,这个接口变量的动态类型为一个*TCPConn:
//$GOROOT/src/net/tcpsock_posix.go
type TCPConn struct {
conn
}
TCPConn内嵌了一个unexported类型:conn,因此TCPConn”继承”了conn的Read和Write方法,后续通过Dial返回值调用的Write和Read方法均是net.conn的方法:
//$GOROOT/src/net/net.go
type conn struct {
fd *netFD
}
func (c *conn) ok() bool { return c != nil && c.fd != nil }
// Implementation of the Conn interface.
// Read implements the Conn Read method.
func (c *conn) Read(b []byte) (int, error) {
if !c.ok() {
return 0, syscall.EINVAL
}
n, err := c.fd.Read(b)
if err != nil && err != io.EOF {
err = &OpError{Op: "read", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
}
return n, err
}
// Write implements the Conn Write method.
func (c *conn) Write(b []byte) (int, error) {
if !c.ok() {
return 0, syscall.EINVAL
}
n, err := c.fd.Write(b)
if err != nil {
err = &OpError{Op: "write", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
}
return n, err
}
下面我们先来通过几个场景来总结一下conn.Read的行为特点。
1、Socket中无数据
连接建立后,如果对方未发送数据到socket,接收方(Server)会阻塞在Read操作上,这和前面提到的“模型”原理是一致的。执行该Read操作的goroutine也会被挂起。runtime会监视该socket,直到其有数据才会重新
调度该socket对应的Goroutine完成read。由于篇幅原因,这里就不列代码了,例子对应的代码文件:go-tcpsock/read_write下的client1.go和server1.go。
2、Socket中有部分数据
如果socket中有部分数据,且长度小于一次Read操作所期望读出的数据长度,那么Read将会成功读出这部分数据并返回,而不是等待所有期望数据全部读取后再返回。
Client端:
//go-tcpsock/read_write/client2.go
... ...
func main() {
if len(os.Args) <= 1 {
fmt.Println("usage: go run client2.go YOUR_CONTENT")
return
}
log.Println("begin dial...")
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Println("dial error:", err)
return
}
defer conn.Close()
log.Println("dial ok")
time.Sleep(time.Second * 2)
data := os.Args[1]
conn.Write([]byte(data))
time.Sleep(time.Second * 10000)
}
Server端:
//go-tcpsock/read_write/server2.go
... ...
func handleConn(c net.Conn) {
defer c.Close()
for {
// read from the connection
var buf = make([]byte, 10)
log.Println("start to read from conn")
n, err := c.Read(buf)
if err != nil {
log.Println("conn read error:", err)
return
}
log.Printf("read %d bytes, content is %s\n", n, string(buf[:n]))
}
}
... ...
我们通过client2.go发送”hi”到Server端:
运行结果:
$go run client2.go hi
2015/11/17 13:30:53 begin dial...
2015/11/17 13:30:53 dial ok
$go run server2.go
2015/11/17 13:33:45 accept a new connection
2015/11/17 13:33:45 start to read from conn
2015/11/17 13:33:47 read 2 bytes, content is hi
...
Client向socket中写入两个字节数据(“hi”),Server端创建一个len = 10的slice,等待Read将读取的数据放入slice;Server随后读取到那两个字节:”hi”。Read成功返回,n =2 ,err = nil。
3、Socket中有足够数据
如果socket中有数据,且长度大于等于一次Read操作所期望读出的数据长度,那么Read将会成功读出这部分数据并返回。这个情景是最符合我们对Read的期待的了:Read将用Socket中的数据将我们传入的slice填满后返回:n = 10, err = nil。
我们通过client2.go向Server2发送如下内容:abcdefghij12345,执行结果如下:
$go run client2.go abcdefghij12345
2015/11/17 13:38:00 begin dial...
2015/11/17 13:38:00 dial ok
$go run server2.go
2015/11/17 13:38:00 accept a new connection
2015/11/17 13:38:00 start to read from conn
2015/11/17 13:38:02 read 10 bytes, content is abcdefghij
2015/11/17 13:38:02 start to read from conn
2015/11/17 13:38:02 read 5 bytes, content is 12345
client端发送的内容长度为15个字节,Server端Read buffer的长度为10,因此Server Read第一次返回时只会读取10个字节;Socket中还剩余5个字节数据,Server再次Read时会把剩余数据读出(如:情形2)。
4、Socket关闭
如果client端主动关闭了socket,那么Server的Read将会读到什么呢?这里分为“有数据关闭”和“无数据关闭”。
“有数据关闭”是指在client关闭时,socket中还有server端未读取的数据,我们在go-tcpsock/read_write/client3.go和server3.go中模拟这种情况:
$go run client3.go hello
2015/11/17 13:50:57 begin dial...
2015/11/17 13:50:57 dial ok
$go run server3.go
2015/11/17 13:50:57 accept a new connection
2015/11/17 13:51:07 start to read from conn
2015/11/17 13:51:07 read 5 bytes, content is hello
2015/11/17 13:51:17 start to read from conn
2015/11/17 13:51:17 conn read error: EOF
从输出结果来看,当client端close socket退出后,server3依旧没有开始Read,10s后第一次Read成功读出了5个字节的数据,当第二次Read时,由于client端 socket关闭,Read返回EOF error。
通过上面这个例子,我们也可以猜测出“无数据关闭”情形下的结果,那就是Read直接返回EOF error。
5、读取操作超时
有些场合对Read的阻塞时间有严格限制,在这种情况下,Read的行为到底是什么样的呢?在返回超时错误时,是否也同时Read了一部分数据了呢?这个实验比较难于模拟,下面的测试结果也未必能反映出所有可能结果。我们编写了client4.go和server4.go来模拟这一情形。
//go-tcpsock/read_write/client4.go
... ...
func main() {
log.Println("begin dial...")
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Println("dial error:", err)
return
}
defer conn.Close()
log.Println("dial ok")
data := make([]byte, 65536)
conn.Write(data)
time.Sleep(time.Second * 10000)
}
//go-tcpsock/read_write/server4.go
... ...
func handleConn(c net.Conn) {
defer c.Close()
for {
// read from the connection
time.Sleep(10 * time.Second)
var buf = make([]byte, 65536)
log.Println("start to read from conn")
c.SetReadDeadline(time.Now().Add(time.Microsecond * 10))
n, err := c.Read(buf)
if err != nil {
log.Printf("conn read %d bytes, error: %s", n, err)
if nerr, ok := err.(net.Error); ok && nerr.Timeout() {
continue
}
return
}
log.Printf("read %d bytes, content is %s\n", n, string(buf[:n]))
}
}
在Server端我们通过Conn的SetReadDeadline方法设置了10微秒的读超时时间,Server的执行结果如下:
$go run server4.go
2015/11/17 14:21:17 accept a new connection
2015/11/17 14:21:27 start to read from conn
2015/11/17 14:21:27 conn read 0 bytes, error: read tcp 127.0.0.1:8888->127.0.0.1:60970: i/o timeout
2015/11/17 14:21:37 start to read from conn
2015/11/17 14:21:37 read 65536 bytes, content is
虽然每次都是10微秒超时,但结果不同,第一次Read超时,读出数据长度为0;第二次读取所有数据成功,没有超时。反复执行了多次,没能出现“读出部分数据且返回超时错误”的情况。
和读相比,Write遇到的情形一样不少,我们也逐一看一下。
1、成功写
前面例子着重于Read,client端在Write时并未判断Write的返回值。所谓“成功写”指的就是Write调用返回的n与预期要写入的数据长度相等,且error = nil。这是我们在调用Write时遇到的最常见的情形,这里不再举例了。
2、写阻塞
TCP连接通信两端的OS都会为该连接保留数据缓冲,一端调用Write后,实际上数据是写入到OS的协议栈的数据缓冲的。TCP是全双工通信,因此每个方向都有独立的数据缓冲。当发送方将对方的接收缓冲区以及自身的发送缓冲区写满后,Write就会阻塞。我们来看一个例子:client5.go和server.go。
//go-tcpsock/read_write/client5.go
... ...
func main() {
log.Println("begin dial...")
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Println("dial error:", err)
return
}
defer conn.Close()
log.Println("dial ok")
data := make([]byte, 65536)
var total int
for {
n, err := conn.Write(data)
if err != nil {
total += n
log.Printf("write %d bytes, error:%s\n", n, err)
break
}
total += n
log.Printf("write %d bytes this time, %d bytes in total\n", n, total)
}
log.Printf("write %d bytes in total\n", total)
time.Sleep(time.Second * 10000)
}
//go-tcpsock/read_write/server5.go
... ...
func handleConn(c net.Conn) {
defer c.Close()
time.Sleep(time.Second * 10)
for {
// read from the connection
time.Sleep(5 * time.Second)
var buf = make([]byte, 60000)
log.Println("start to read from conn")
n, err := c.Read(buf)
if err != nil {
log.Printf("conn read %d bytes, error: %s", n, err)
if nerr, ok := err.(net.Error); ok && nerr.Timeout() {
continue
}
}
log.Printf("read %d bytes, content is %s\n", n, string(buf[:n]))
}
}
... ...
Server5在前10s中并不Read数据,因此当client5一直尝试写入时,写到一定量后就会发生阻塞:
$go run client5.go
2015/11/17 14:57:33 begin dial...
2015/11/17 14:57:33 dial ok
2015/11/17 14:57:33 write 65536 bytes this time, 65536 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 131072 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 196608 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 262144 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 327680 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 393216 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 458752 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 524288 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 589824 bytes in total
2015/11/17 14:57:33 write 65536 bytes this time, 655360 bytes in total
在Darwin上,这个size大约在679468bytes。后续当server5每隔5s进行Read时,OS socket缓冲区腾出了空间,client5就又可以写入了:
$go run server5.go
2015/11/17 15:07:01 accept a new connection
2015/11/17 15:07:16 start to read from conn
2015/11/17 15:07:16 read 60000 bytes, content is
2015/11/17 15:07:21 start to read from conn
2015/11/17 15:07:21 read 60000 bytes, content is
2015/11/17 15:07:26 start to read from conn
2015/11/17 15:07:26 read 60000 bytes, content is
....
client端:
2015/11/17 15:07:01 write 65536 bytes this time, 720896 bytes in total
2015/11/17 15:07:06 write 65536 bytes this time, 786432 bytes in total
2015/11/17 15:07:16 write 65536 bytes this time, 851968 bytes in total
2015/11/17 15:07:16 write 65536 bytes this time, 917504 bytes in total
2015/11/17 15:07:27 write 65536 bytes this time, 983040 bytes in total
2015/11/17 15:07:27 write 65536 bytes this time, 1048576 bytes in total
.... ...
3、写入部分数据
Write操作存在写入部分数据的情况,比如上面例子中,当client端输出日志停留在“write 65536 bytes this time, 655360 bytes in total”时,我们杀掉server5,这时我们会看到client5输出以下日志:
...
2015/11/17 15:19:14 write 65536 bytes this time, 655360 bytes in total
2015/11/17 15:19:16 write 24108 bytes, error:write tcp 127.0.0.1:62245->127.0.0.1:8888: write: broken pipe
2015/11/17 15:19:16 write 679468 bytes in total
显然Write并非在655360这个地方阻塞的,而是后续又写入24108后发生了阻塞,server端socket关闭后,我们看到Wrote返回er != nil且n = 24108,程序需要对这部分写入的24108字节做特定处理。
4、写入超时
如果非要给Write增加一个期限,那我们可以调用SetWriteDeadline方法。我们copy一份client5.go,形成client6.go,在client6.go的Write之前增加一行timeout设置代码:
conn.SetWriteDeadline(time.Now().Add(time.Microsecond * 10))
启动server6.go,启动client6.go,我们可以看到写入超时的情况下,Write的返回结果:
$go run client6.go
2015/11/17 15:26:34 begin dial...
2015/11/17 15:26:34 dial ok
2015/11/17 15:26:34 write 65536 bytes this time, 65536 bytes in total
... ...
2015/11/17 15:26:34 write 65536 bytes this time, 655360 bytes in total
2015/11/17 15:26:34 write 24108 bytes, error:write tcp 127.0.0.1:62325->127.0.0.1:8888: i/o timeout
2015/11/17 15:26:34 write 679468 bytes in total
可以看到在写入超时时,依旧存在部分数据写入的情况。
综上例子,虽然Go给我们提供了阻塞I/O的便利,但在调用Read和Write时依旧要综合需要方法返回的n和err的结果,以做出正确处理。net.conn实现了io.Reader和io.Writer接口,因此可以试用一些wrapper包进行socket读写,比如bufio包下面的Writer和Reader、io/ioutil下的函数等。
Goroutine safe
基于goroutine的网络架构模型,存在在不同goroutine间共享conn的情况,那么conn的读写是否是goroutine safe的呢?在深入这个问题之前,我们先从应用意义上来看read操作和write操作的goroutine-safe必要性。
对于read操作而言,由于TCP是面向字节流,conn.Read无法正确区分数据的业务边界,因此多个goroutine对同一个conn进行read的意义不大,goroutine读到不完整的业务包反倒是增加了业务处理的难度。对与Write操作而言,倒是有多个goroutine并发写的情况。不过conn读写是否goroutine-safe的测试不是很好做,我们先深入一下runtime代码,先从理论上给这个问题定个性:
net.conn只是*netFD的wrapper结构,最终Write和Read都会落在其中的fd上:
type conn struct {
fd *netFD
}
netFD在不同平台上有着不同的实现,我们以net/fd_unix.go中的netFD为例:
// Network file descriptor.
type netFD struct {
// locking/lifetime of sysfd + serialize access to Read and Write methods
fdmu fdMutex
// immutable until Close
sysfd int
family int
sotype int
isConnected bool
net string
laddr Addr
raddr Addr
// wait server
pd pollDesc
}
我们看到netFD中包含了一个runtime实现的fdMutex类型字段,从注释上来看,该fdMutex用来串行化对该netFD对应的sysfd的Write和Read操作。从这个注释上来看,所有对conn的Read和Write操作都是有fdMutex互斥的,从netFD的Read和Write方法的实现也证实了这一点:
func (fd *netFD) Read(p []byte) (n int, err error) {
if err := fd.readLock(); err != nil {
return 0, err
}
defer fd.readUnlock()
if err := fd.pd.PrepareRead(); err != nil {
return 0, err
}
for {
n, err = syscall.Read(fd.sysfd, p)
if err != nil {
n = 0
if err == syscall.EAGAIN {
if err = fd.pd.WaitRead(); err == nil {
continue
}
}
}
err = fd.eofError(n, err)
break
}
if _, ok := err.(syscall.Errno); ok {
err = os.NewSyscallError("read", err)
}
return
}
func (fd *netFD) Write(p []byte) (nn int, err error) {
if err := fd.writeLock(); err != nil {
return 0, err
}
defer fd.writeUnlock()
if err := fd.pd.PrepareWrite(); err != nil {
return 0, err
}
for {
var n int
n, err = syscall.Write(fd.sysfd, p[nn:])
if n > 0 {
nn += n
}
if nn == len(p) {
break
}
if err == syscall.EAGAIN {
if err = fd.pd.WaitWrite(); err == nil {
continue
}
}
if err != nil {
break
}
if n == 0 {
err = io.ErrUnexpectedEOF
break
}
}
if _, ok := err.(syscall.Errno); ok {
err = os.NewSyscallError("write", err)
}
return nn, err
}
每次Write操作都是受lock保护,直到此次数据全部write完。因此在应用层面,要想保证多个goroutine在一个conn上write操作的Safe,需要一次write完整写入一个“业务包”;一旦将业务包的写入拆分为多次write,那就无法保证某个Goroutine的某“业务包”数据在conn发送的连续性。
同时也可以看出即便是Read操作,也是lock保护的。多个Goroutine对同一conn的并发读不会出现读出内容重叠的情况,但内容断点是依 runtime调度来随机确定的。存在一个业务包数据,1/3内容被goroutine-1读走,另外2/3被另外一个goroutine-2读 走的情况。比如一个完整包:world,当goroutine的read slice size < 5时,存在可能:一个goroutine读到 “worl”,另外一个goroutine读出”d”。
四、Socket属性
原生Socket API提供了丰富的sockopt设置接口,但Golang有自己的网络架构模型,golang提供的socket options接口也是基于上述模型的必要的属性设置。包括
- SetKeepAlive
- SetKeepAlivePeriod
- SetLinger
- SetNoDelay (默认no delay)
- SetWriteBuffer
- SetReadBuffer
不过上面的Method是TCPConn的,而不是Conn的,要使用上面的Method的,需要type assertion:
tcpConn, ok := c.(*TCPConn)
if !ok {
//error handle
}
tcpConn.SetNoDelay(true)
对于listener socket, golang默认采用了 SO_REUSEADDR,这样当你重启 listener程序时,不会因为address in use的错误而启动失败。而listen backlog的默认值是通过获取系统的设置值得到的。不同系统不同:mac 128, linux 512等。
五、关闭连接
和前面的方法相比,关闭连接算是最简单的操作了。由于socket是全双工的,client和server端在己方已关闭的socket和对方关闭的socket上操作的结果有不同。看下面例子:
//go-tcpsock/conn_close/client1.go
... ...
func main() {
log.Println("begin dial...")
conn, err := net.Dial("tcp", ":8888")
if err != nil {
log.Println("dial error:", err)
return
}
conn.Close()
log.Println("close ok")
var buf = make([]byte, 32)
n, err := conn.Read(buf)
if err != nil {
log.Println("read error:", err)
} else {
log.Printf("read % bytes, content is %s\n", n, string(buf[:n]))
}
n, err = conn.Write(buf)
if err != nil {
log.Println("write error:", err)
} else {
log.Printf("write % bytes, content is %s\n", n, string(buf[:n]))
}
time.Sleep(time.Second * 1000)
}
//go-tcpsock/conn_close/server1.go
... ...
func handleConn(c net.Conn) {
defer c.Close()
// read from the connection
var buf = make([]byte, 10)
log.Println("start to read from conn")
n, err := c.Read(buf)
if err != nil {
log.Println("conn read error:", err)
} else {
log.Printf("read %d bytes, content is %s\n", n, string(buf[:n]))
}
n, err = c.Write(buf)
if err != nil {
log.Println("conn write error:", err)
} else {
log.Printf("write %d bytes, content is %s\n", n, string(buf[:n]))
}
}
... ...
上述例子的执行结果如下:
$go run server1.go
2015/11/17 17:00:51 accept a new connection
2015/11/17 17:00:51 start to read from conn
2015/11/17 17:00:51 conn read error: EOF
2015/11/17 17:00:51 write 10 bytes, content is
$go run client1.go
2015/11/17 17:00:51 begin dial...
2015/11/17 17:00:51 close ok
2015/11/17 17:00:51 read error: read tcp 127.0.0.1:64195->127.0.0.1:8888: use of closed network connection
2015/11/17 17:00:51 write error: write tcp 127.0.0.1:64195->127.0.0.1:8888: use of closed network connection
从client1的结果来看,在己方已经关闭的socket上再进行read和write操作,会得到”use of closed network connection” error;
从server1的执行结果来看,在对方关闭的socket上执行read操作会得到EOF error,但write操作会成功,因为数据会成功写入己方的内核socket缓冲区中,即便最终发不到对方socket缓冲区了,因为己方socket并未关闭。因此当发现对方socket关闭后,己方应该正确合理处理自己的socket,再继续write已经无任何意义了。
六、小结
本文比较基础,但却很重要,毕竟golang是面向大规模服务后端的,对通信环节的细节的深入理解会大有裨益。另外Go的goroutine+阻塞通信的网络通信模型降低了开发者心智负担,简化了通信的复杂性,这点尤为重要。
本文代码实验环境:go 1.5.1 on Darwin amd64以及部分在ubuntu 14.04 amd64。
本文demo代码在这里可以找到。