Writing a log, dumping data, looking for file to be used in Bulk insert…
There are many situations when you would want to have access to files from inside your SQL code on Microsoft SQL Server.
Did you know that you actually can do this? No? Check below for code snippets to perform various operations on files. It is presented in form of the functions but you are actually not limited to that
Prerequisites and assumptions
Your script should have sufficient rights to perform required access to files (not necessarily local).
Scripting.FileSystemObject should be present at your SQL Server location and accessible.
This post will takes you through the T-SQL Script to monitor SQL Server Memory Usage. In previous blog post we have explained the parameters involved in understanding sql server memory usage. There are total 7 scripts to monitor SQL Server Memory Usage.
Buffer Pool Usage
System Memory Information
SQL Server Process Memory Usage Information
Buffer Usage by Database
Object Wise Buffer Usage
Top 25 Costliest Stored Procedures – Logical Reads
Top Performance Counters
Script to Monitor SQL Server Memory Usage: Buffer Pool Usage
Results:
BPool_Committed_MB: Actual memory committed/used by the process (SQL Server).
BPool_Commit_Tgt_MB: Actual memory SQL Server tried to consume.
BPool_Visible_MB: Number of 8-KB buffers in the buffer pool that are directly accessible in the process virtual address space (SQL Server VAS).
Analysis:
BPool_Commit_Tgt_MB > BPool_Committed_MB: SQL Server Memory Manager tries to obtain additional memory
BPool_Commit_Tgt_MB < BPool_Committed_MB: SQL Server Memory Manager tries to shrink the amount of memory committed
If the value of BPool_Visible_MB is too low: We might receive out of memory errors or memory dump will be created.
Script to Monitor SQL Server Memory Usage: SQL Server Process Memory Usage
Results:
physical_memory_in_use: Indicates the process working set in KB, as reported by operating system, as well as tracked allocations by using large page APIs
locked_page_allocations: Specifies memory pages locked in memory
virtual_address_space_committed: Indicates the amount of reserved virtual address space that has been committed or mapped to physical pages.
available_commit_limit: Indicates the amount of memory that is available to be committed by the process (SQL server)
page_fault_count: Indicates the number of page faults that are incurred by the SQL Server process
Analysis:
physical_memory_in_use: We can’t figure out the exact amount of physical memory using by sqlservr.exe using task manager but this column showcase the actual amount of physical memory using by SQL Server.
locked_page_allocations: If this is > 0 means Locked Pages is enabled for SQL Server which is one of the best practice
available_commit_limit: This indciates the available amount of memory that can be committed by the process sqlservr.exe
page_fault_count: Pages fetching from the page file on the hard disk instead of from physical memory. Consistently high number of hard faults per second represents Memory pressure.
Script to Monitor SQL Server Memory Usage: Object Wise Buffer Usage
Results:
Object: Name of the Object
Type: Type of the object Ex: USER_TABLE
Index: Name of the Index
Index_Type: Type of the Index “Clustered / Non Clustered / HEAP” etc
buffer_pages: Object wise number of pages is in buffer pool
buffer_mb: Object wise buffer usage in MB
Analysis:
From the previous script we can get the top databases using memory. This script helps you out in finding the top objects that are using the buffer pool. Top objects will tell you the objects which are using the major portion of the buffer pool.If you find anything suspicious then you can dig into it.
Script to Monitor SQL Server Memory Usage: Top Performance Counters – Memory
Results:
Total Server Memory: Shows how much memory SQL Server is using. The primary use of SQL Server’s memory is for the buffer pool, but some memory is also used for storing query plans and keeping track of user process information.
Target Server Memory: This value shows how much memory SQL Server attempts to acquire. If you haven’t configured a max server memory value for SQL Server, the target amount of memory will be about 5MB less than the total available system memory.
Connection Memory (GB): The Connection Memory specifies the total amount of dynamic memory the server is using for maintaining connections
Lock Memory (GB): Shows the total amount of memory the server is using for locks
SQL Cache Memory: Total memory reserved for dynamic SQL statements.
Optimizer Memory: Memory reserved for query optimization.
Granted Workspace Memory: Total amount of memory currently granted to executing processes such as hash, sort, bulk copy, and index creation operations.
Cursor memory usage: Memory using for cursors
Free pages: Amount of free space in pages which are commited but not currently using by SQL Server
Reserved Pages: Shows the number of buffer pool reserved pages.
Stolen pages (MB): Memory used by SQL Server but not for Database pages.It is used for sorting or hashing operations, or “as a generic memory store for allocations to store internal data structures such as locks, transaction context, and connection information.
Cache Pages: Number of 8KB pages in cache.
Page life expectancy: Average how long each data page is staying in buffer cache before being flushed out to make room for other pages
Free list stalls / sec: Number of times a request for a “free” page had to wait for one to become available.
Checkpoint Pages/sec: Checkpoint Pages/sec shows the number of pages that are moved from buffer to disk per second during a checkpoint process
Lazy writes / sec: How many times per second lazy writer has to flush dirty pages out of the buffer cache instead of waiting on a checkpoint.
Memory Grants Outstanding: Number of processes that have successfully acquired workspace memory grant.
Memory Grants Pending: Number of processes waiting on a workspace memory grant.
process_physical_memory_low: Process is responding to low physical memory notification
process_virtual_memory_low: Indicates that low virtual memory condition has been detected
Min Server Memory: Minimum amount of memory SQL Server should acquire
Max Server Memory: Maximum memory that SQL Server can acquire from OS
Buffer cache hit ratio: Percentage of pages that were found in the buffer pool without having to incur a read from disk.
Analysis:
Total Server Memory is almost same as Target Server Memory: Good Health
Total Server Memory is much smaller than Target Server Memory: There is a Memory Pressure or Max Server Memory is set to too low.
Connection Memory: When high, check the number of user connections and make sure it’s under expected value as per your business
Optimizer Memory: Ideally, the value should remain relatively static. If this isn’t the case you might be using dynamic SQL execution excessively.
Higher the value for Stolen Pages: Find the costly queries / procs and tune them
Higher the value for Checkpoint Pages/sec: Problem with I/O, Do not depend on Automatic Checkpoints and use In-direct checkpoints.
Page life expectancy: Usually 300 to 400 sec for each 4 GB of memory. Lesser the value means memory pressure
Free list stalls / sec: High value indicates that the server could use additional memory.
Memory Grants Outstanding: Higher value indicates peak user activity
Memory Grants Pending: Higher value indicates SQL Server need more memory
process_physical_memory_low & process_virtual_memory_low: Both are equals to 0 means no internal memory pressure
Min Server Memory: If it is 0 means default value didnt get changed, it’ll always be better to have a minimum amount of memory allocated to SQL Server
Max Server Memory: If it is default to 2147483647, change the value with the correct amount of memory that you can allow SQL Server to utilize.
Buffer cache hit ratio: This ratio should be in between 95 and 100. Lesser value indicates memory pressure
WHEREcounter_name=‘Buffer cache hit ratio base’AND
OBJECT_NAME=@Instancename+‘Buffer Manager’)bON
a.OBJECT_NAME=b.OBJECT_NAMEWHEREa.counter_name=‘Buffer cache hit ratio’
ANDa.OBJECT_NAME=@Instancename+‘Buffer Manager’
)ASD;
Script to Monitor SQL Server Memory Usage: DBCC MEMORYSTATUS
Finally DBCC MemoryStatus:
It gives as much as memory usage information based on object wise / component wise.
First table gives us the complete details of server and process memory usage details and memory alert indicators.
We can also get memory usage by buffer cache, Service Broker, Temp tables, Procedure Cache, Full Text, XML, Memory Pool Manager, Audit Buffer, SQLCLR, Optimizer, SQLUtilities, Connection Pool etc.
Summary:
These Scripts will help you in understanding the current memory usage by SQL Server. To maintain a healthy database management system:
Monitor the system for few business days in peak hours and fix the baselines
Identify the correct required configurations for your database server and make the required changes
Identify top 10 queries / procedures based on Memory and CPU usage
Fine tune these top 10 queries / procedures
Note:
These scripts are tested on SQL Server 2008, 2008 R2, 2012 and 2014. As we always suggests please test these scripts on Dev/Test environment before using them on production systems.
References:
Would like to thank famous MVPs / MCM / bloggers (Glenn Berry, Brent Ozar, Jonathan Kehayias, John Sansom) for the tremendous explanation on sql server internals. Their articles are very informative and helpful in understanding SQL Server internals.
Those who have been working with SQL Server administration for a while now undoubtedly have at times referred to the old SQL Server system tables in order to automate some processes, or document their tables by for example combining the sysobjects and syscolumns tables. As per SQL Server 2005 and onwards, Microsoft added a number of Dynamic Management Views (DMV) that take simplify all kinds of management tasks.
List of SQL Server 2000 system tables and their 2005 equivalent management views, as well as a brief description what kind of information to find in the views.
Dynamic Management Views existing in the Master database
SQL Server 2000
SQL Server2005
Description
sysaltfiles
sys.master_files
Contains a row per file of a database as stored in the master database.
syscacheobjects
sys.dm_exec_cached_plans
Returns a row for each query plan that is cached by SQL Server for faster query execution.
sys.dm_exec_plan_attributes
Returns one row per plan attribute for the plan specified by the plan handle.
sys.dm_exec_sql_text
Returns the text of the SQL batch that is identified by the specified sql_handle.
sys.dm_exec_cached_plan_dependent_objects
Returns a row for each Transact-SQL execution plan, common language runtime (CLR) execution plan, and cursor associated with a plan.
syscharsets
sys.syscharsets
Contains one row for each character set and sort order defined for use by the SQL Server Database Engine.
sysconfigures
sys.configurations
Contains a row per server-wide configuration option value in the system.
syscurconfigs
sys.configurations
Contains a row per server-wide configuration option value in the system.
sysdatabases
sys.databases
Contains one row per database in the instance of Microsoft SQL Server.
sysdevices
sys.backup_devices
Contains a row for each backup-device registered by using sp_addumpdevice or created in SQL Server Management Studio.
syslanguages
sys.syslanguages
Contains one row for each language present in the instance of SQL Server.
syslockinfo
sys.dm_tran_locks
Returns information about currently active lock manager resources
syslocks[
sys.dm_tran_locks
Returns information about currently active lock manager resources
syslogins
sys.server_principals
Contains a row for every server-level principal.
sys.sql_logins
Returns one row for every SQL login.
sysmessages
sys.messages
Contains a row for each message_id or language_id of the error messages in the system, for both system-defined and user-defined messages.
sysoledbusers
sys.linked_logins
Returns a row per linked-server-login mapping, for use by RPC and distributed queries from local server to the corresponding linked server.
sysopentapes
sys.dm_io_backup_tapes
Returns the list of tape devices and the status of mount requests for backups.
sysperfinfo
sys.dm_os_performance_counters
Returns a row per performance counter maintained by the server.
sysprocesses
sys.dm_exec_connections
Returns information about the connections established to this instance of SQL Server and the details of each connection.
sys.dm_exec_sessions
Returns one row per authenticated session on SQL Server.
sys.dm_exec_requests
Returns information about each request that is executing within SQL Server.
sysremotelogins
sys.remote_logins
Returns a row per remote-login mapping. This catalog view is used to map incoming local logins that claim to be coming from a corresponding server to an actual local login.
sysservers
sys.servers
Contains a row per linked or remote server registered, and a row for the local server that has server_id = 0.
Dynamic Management Views existing in every database.
SQL Server 2000
SQL Server 2005
Description
fn_virtualfilestats
sys.dm_io_virtual_file_stats
Returns I/O statistics for data and log files.
syscolumns
sys.columns
Returns a row for each column of an object that has columns, such as views or tables.
syscomments
sys.sql_modules
Returnsa row for each object that is an SQL language-defined module. Objectsof type ‘P’, ‘RF’, ‘V’, ‘TR’, ‘FN’, ‘IF’, ‘TF’, and ‘R’ have an associated SQL module.
sysconstraints
sys.check_constraints
Contains a row for each object that is a CHECK constraint, with sys.objects.type = ‘C’.
sys.default_constraints
Contains a row for each object that is a default definition (created as part of a CREATE TABLE or ALTER TABLE statement instead of a CREATE DEFAULT statement), with sys.objects.type = ‘D’.
sys.key_constraints
Contains a row for each object that is a primary key or unique constraint. Includes sys.objects.type ‘PK’ and ‘UQ’.
sys.foreign_keys
Contains a row per object that is a FOREIGN KEY constraint, with sys.object.type = ‘F’.
sysdepends
sys.sql_expression_dependencies
Contains one row for each by-name dependency on a user-defined entity in the current database. A dependency between two entities is created when one entity, called the referenced entity, appears by name in a persisted SQL expression of another entity, called the referencing entity.
sysfilegroups
sys.filegroups
Contains a row for each data space that is a filegroup.
sysfiles
sys.database_files
Contains a row per file of a database as stored in the database itself. This is a per-database view.
sysforeignkeys
sys.foreign_key_columns
Contains a row for each column, or set of columns, that comprise a foreign key.
sysindexes
sys.indexes
Contains a row per index or heap of a tabular object, such as a table, view, or table-valued function.
sys.partitions
Contains a row for each partition of all the tables and most types of indexes in the database. Special index types like Fulltext, Spatial, and XML are not included in this view. All tables and indexes in SQL Server contain at least one partition, whether or not they are explicitly partitioned.
sys.allocation_units
Contains a row for each allocation unit in the database.
sys.dm_db_partition_stats
Returns page and row-count information for every partition in the current database.
sysindexkeys
sys.index_columns
Contains one row per column that is part of a sys.indexes index or unordered table (heap).
sysmembers
sys.database_role_members
Returns one row for each member of each database role.
sysobjects
sys.objects
Contains a row for each user-defined, schema-scoped object that is created within a database.
syspermissions
sys.database_permissions
Returns a row for every permission or column-exception permission in the database. For columns, there is a row for every permission that is different from the corresponding object-level permission. If the column permission is the same as the corresponding object permission, there will be no row for it and the actual permission used will be that of the object.
sys.server_permissions
Returns one row for each server-level permission.
sysprotects
sys.database_permissions
Returns a row for every permission or column-exception permission in the database. For columns, there is a row for every permission that is different from the corresponding object-level permission. If the column permission is the same as the corresponding object permission, there will be no row for it and the actual permission used will be that of the object.
sys.server_permissions
Returns one row for each server-level permission.
sysreferences
sys.foreign_keys
Contains a row per object that is a FOREIGN KEY constraint, with sys.object.type = ‘F’.
systypes
sys.types
Contains a row for each system and user-defined type.
There is a multitude of data to be mined from within the Microsoft SQL Server system views. This data is used to present information back to the end user of the SQL Server Management Studio (SSMS) and all third party management tools that are available for SQL Server Professionals. Be it database backup information, file statistics, indexing information, or one of the thousands of other metrics that the instance maintains, this data is readily available for direct querying and assimilation into your “home-grown” monitoring solutions as well. This tip focuses on that first metric: database backup information. Where it resides, how it is structured, and what data is available to be mined.
Solution
The msdb system database is the primary repository for storage of SQL Agent, backup, Service Broker, Database Mail, Log Shipping, restore, and maintenance plan metadata. We will be focusing on the handful of system views associated with database backups for this tip:
dbo.backupset: provides information concerning the most-granular details of the backup process
dbo.backupmediafamily: provides metadata for the physical backup files as they relate to backup sets
dbo.backupfile: this system view provides the most-granular information for the physical backup files
Based upon these tables, we can create a variety of queries to collect a detailed insight into the status of backups for the databases in any given SQL Server instance.
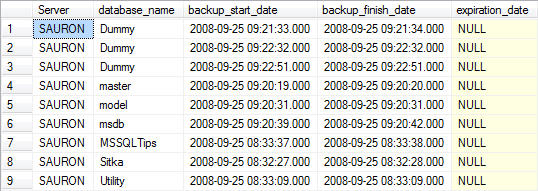
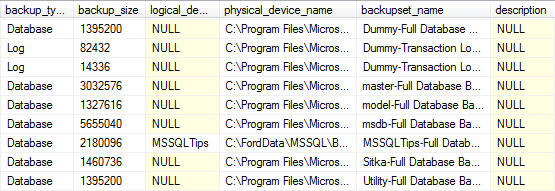
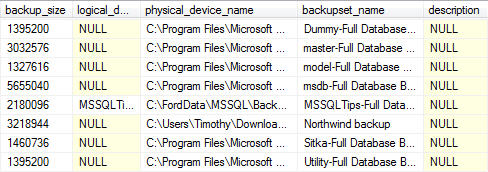
Database Backups for all databases For Previous Week
---------------------------------------------------------------------------------
--Database Backups for all databases For Previous Week
---------------------------------------------------------------------------------
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
msdb.dbo.backupset.database_name,
msdb.dbo.backupset.backup_start_date,
msdb.dbo.backupset.backup_finish_date,
msdb.dbo.backupset.expiration_date,
CASE msdb..backupset.type
WHEN 'D' THEN 'Database'
WHEN 'L' THEN 'Log'
END AS backup_type,
msdb.dbo.backupset.backup_size,
msdb.dbo.backupmediafamily.logical_device_name,
msdb.dbo.backupmediafamily.physical_device_name,
msdb.dbo.backupset.name AS backupset_name,
msdb.dbo.backupset.description
FROM msdb.dbo.backupmediafamily
INNER JOIN msdb.dbo.backupset ON msdb.dbo.backupmediafamily.media_set_id = msdb.dbo.backupset.media_set_id
WHERE (CONVERT(datetime, msdb.dbo.backupset.backup_start_date, 102) >= GETDATE() - 7)
ORDER BY
msdb.dbo.backupset.database_name,
msdb.dbo.backupset.backup_finish_date
Note: for readability the output was split into two screenshots.
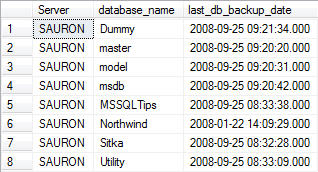
Most Recent Database Backup for Each Database
-------------------------------------------------------------------------------------------
--Most Recent Database Backup for Each Database
-------------------------------------------------------------------------------------------
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
msdb.dbo.backupset.database_name,
MAX(msdb.dbo.backupset.backup_finish_date) AS last_db_backup_date
FROM msdb.dbo.backupmediafamily
INNER JOIN msdb.dbo.backupset ON msdb.dbo.backupmediafamily.media_set_id = msdb.dbo.backupset.media_set_id
WHERE msdb..backupset.type = 'D'
GROUP BY
msdb.dbo.backupset.database_name
ORDER BY
msdb.dbo.backupset.database_name
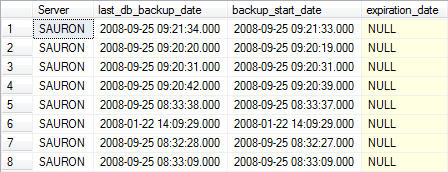
Most Recent Database Backup for Each Database – Detailed
You can join the two result sets together by using the following query in order to return more detailed information about the last database backup for each database. The LEFT JOIN allows you to match up grouped data with the detailed data from the previous query without having to include the fields you do not wish to group on in the query itself.
-------------------------------------------------------------------------------------------
--Most Recent Database Backup for Each Database - Detailed
-------------------------------------------------------------------------------------------
SELECT
A.[Server],
A.last_db_backup_date,
B.backup_start_date,
B.expiration_date,
B.backup_size,
B.logical_device_name,
B.physical_device_name,
B.backupset_name,
B.description
FROM
(
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
msdb.dbo.backupset.database_name,
MAX(msdb.dbo.backupset.backup_finish_date) AS last_db_backup_date
FROM msdb.dbo.backupmediafamily
INNER JOIN msdb.dbo.backupset ON msdb.dbo.backupmediafamily.media_set_id = msdb.dbo.backupset.media_set_id
WHERE msdb..backupset.type = 'D'
GROUP BY
msdb.dbo.backupset.database_name
) AS A
LEFT JOIN
(
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
msdb.dbo.backupset.database_name,
msdb.dbo.backupset.backup_start_date,
msdb.dbo.backupset.backup_finish_date,
msdb.dbo.backupset.expiration_date,
msdb.dbo.backupset.backup_size,
msdb.dbo.backupmediafamily.logical_device_name,
msdb.dbo.backupmediafamily.physical_device_name,
msdb.dbo.backupset.name AS backupset_name,
msdb.dbo.backupset.description
FROM msdb.dbo.backupmediafamily
INNER JOIN msdb.dbo.backupset ON msdb.dbo.backupmediafamily.media_set_id = msdb.dbo.backupset.media_set_id
WHERE msdb..backupset.type = 'D'
) AS B
ON A.[server] = B.[server] AND A.[database_name] = B.[database_name] AND A.[last_db_backup_date] = B.[backup_finish_date]
ORDER BY
A.database_name
Note: for readability the output was split into two screenshots.
Databases Missing a Data (aka Full) Back-Up Within Past 24 Hours
At this point we’ve seen how to look at the history for databases that have been backed up. While this information is important, there is an aspect to backup metadata that is slightly more important – which of the databases you administer have not been getting backed up. The following query provides you with that information (with some caveats.)
-------------------------------------------------------------------------------------------
--Databases Missing a Data (aka Full) Back-Up Within Past 24 Hours
-------------------------------------------------------------------------------------------
--Databases with data backup over 24 hours old
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
msdb.dbo.backupset.database_name,
MAX(msdb.dbo.backupset.backup_finish_date) AS last_db_backup_date,
DATEDIFF(hh, MAX(msdb.dbo.backupset.backup_finish_date), GETDATE()) AS [Backup Age (Hours)]
FROM msdb.dbo.backupset
WHERE msdb.dbo.backupset.type = 'D'
GROUP BY msdb.dbo.backupset.database_name
HAVING (MAX(msdb.dbo.backupset.backup_finish_date) < DATEADD(hh, - 24, GETDATE()))
UNION
--Databases without any backup history
SELECT
CONVERT(CHAR(100), SERVERPROPERTY('Servername')) AS Server,
master.dbo.sysdatabases.NAME AS database_name,
NULL AS [Last Data Backup Date],
9999 AS [Backup Age (Hours)]
FROM
master.dbo.sysdatabases LEFT JOIN msdb.dbo.backupset
ON master.dbo.sysdatabases.name = msdb.dbo.backupset.database_name
WHERE msdb.dbo.backupset.database_name IS NULL AND master.dbo.sysdatabases.name <> 'tempdb'
ORDER BY
msdb.dbo.backupset.database_name
Now let me explain those caveats, and this query. The first part of the query returns all records where the last database (full) backup is older than 24 hours from the current system date. This data is then combined via the UNION statement to the second portion of the query. That second statement returns information on all databases that have no backup history. I’ve taken the liberty of singling tempdb out from the result set since you do not back up that system database. It is recreated each time the SQL Server services are restarted. That is caveat #1. Caveat #2 is the arbitrary value I’ve assigned to the aging value for databases without any backup history. I’ve set that value at 9999 hours because in my environment I want to place a higher emphasis on those databases that have never been backed up.
Most tips works for SSMS higher 2008 but some of them only for SSMS 2016 and above.
Great thanks to:
Kendra Little
Slava Murygin
Mike Milligan
Kenneth Fisher
William Durkin
John Morehouse
Phil Factor
Klaus Aschenbrenner
Latish Sehgal
Arvind Shyamsundar
SQLMatters
MSSQLTips
Anthony Zanevsky, Andrew Zanevsky and Katrin Zanevsky
Andy Mallon
Aaron Bertrand
Import and Export Settings
Tools > Options > Environment > Import and Export Settings
You can configure so many settings in SSMS and then export it and use on all your computers. Below link provide detailed instruction and awesome Dark theme configuration: Making SSMS Pretty: My Dark Theme
3 Shortcuts can not be changed: Alt + F1, Ctrl + 1 and Ctrl + 2. For another 9 shortcuts my recommendation awesome open source Brent Ozar teams procedures and with some limitations Adam Machanic sp_WhoIsActive:
Right click on database name > Tasks > Generate Scripts …
Selecting a block of text using the ALT Key
By holding down the ALT key as you select a block of text you can control the width of the selection region as well as the number of rows. Also you can activate multi line mode with Shift + Alt keys and using keyboard arrows to format multi line code.
Script Table and Column Names by Dragging from Object Explorer
Save keystrokes by dragging Drag the Columns folder for a table in to auto-type all column names in the table in a single line.
Warning: this doesn’t include [brackets] around the column names, so if your columns contain spaces or special characters at the beginning, this shortcut isn’t for you
Dragging the table name over will auto-type the schema and table name, with brackets.
Disable Copy of Empty Text
Select a block of text to copy;
Move the cursor the place where you want to paste the code;
Accidentally press Ctrl+C again instead of Ctrl+V;
Block of copied text is replaced by an empty block;
This behavior can be disabled in SSMS: go to Tools > Options > Text Editor > All Languages > General > 'Apply Cut or Copy Commands to blank lines when there is no selection' and uncheck the checkbox.
Client Statistics
When you enable that option for your session, SQL Server Management Studio will give you more information about the client side processing of your query.
The Network Statistics shows you the following information:
Number of Server Roundtrips
TDS Packets sent from Client
TDS Packets received from Server
Bytes sent from Client
Bytes received from Server
The Time Statistics additionally shows you the following information:
Client Processing Time
Total Execution Time
Wait Time on Server Replies
Configure Object Explorer to Script Compression and Partition Schemes for Indexes
Is this index compressed or partitioned?
By default, you wouldn’t know just by scripting out the index from Object Explorer. If you script out indexes this way to check them into source code, or to tweak the definition slightly, this can lead you to make mistakes.
You can make sure you’re aware when indexes have compression or are partitioned by changing your scripting settings:
Click Tools – > Options -> SQL Server Object Explorer -> Scripting
Scroll down in the right pane of options and set both of these to True
Script Data Compression Options
Script Partition Schemes
Click OK
Using GO X to Execute a Batch or Statement Multiple Times
The GO command marks the end of a batch of statements that should be sent to SQL Server for processing, and then compiled into a single execution plan. By specifying a number after the ‘GO’ the batch can be run specified number of times. This can be useful if, for instance, you want to create test data by running an insert statement a number of times. Note that this is not a Transact SQL statement and will only work in Management Studio (and also SQLCMD or OSQL). For instance the following SQL can be run in SSMS :
CREATETABLETestData(ID INT IDENTITY (1,1), CreatedDate DATETIME)
GO
INSERT INTO TestData(CreatedDate) SELECT GetDate()
GO 10
This will run the insert statement 10 times and therefore insert 10 rows into the TestData table. In this case this is a simpler alternative than creating a cursor or while loop.
SSMS Template Replacement
One under-used feature of Management Studio is the template replacement feature. SSMS comes with a library of templates, but you can also make your own templates for reusable scripts.
In your saved .sql script, just use the magic incantation to denote the parameters for replacement. The format is simple: <label, datatype, default value>
Then, when you open the .sql script, you hit CTRL + Shift + M, and SSMS will give you a pop-up to enter your replacement values.
Color coding of connections
SQL Server Management Studio has the capability of coloring the bar at the bottom of each query window, with the color dependent on which server is connected. This can be useful in order to provide a visual check of the server that a query is to be run against, for instance to color code production instances as red, development as green and amber as test. This can also be used in conjunction with Registered Servers and CMS (Central Management Server). To add a color bar when connecting to the server click on the Options button in the Connect to Database Engine window and then select the Connection Properties window. Select the check box towards the bottom of the window and use the ‘Select…’ button to choose a color.
SQLCMD mode
Switching on SQLCMD mode enables a number of useful extra scripting style commands in SSMS. In particular you can use it to change to the connection credentials within the query window, so that you can run a query against multiple servers from the same query window. There are more details of how to do this here: Changing the SQL Server connection within an SSMS Query Windows using SQLCMD Mode
Script multiple objects using the Object Explorer Details Windows
Individual database objects, such as a table or stored procedure, can be scripted within SSMS by right clicking on the object within Object Explorer and selecting the appropriate item in the drop down menu. However if you have a lot of objects to script that can quickly become time consuming. Fortunately it’s possible to select multiple objects and script them up all together in a single query window. To do this just open the Object Explorer Details window from the View menu (or press the F7 key). If you want to script up multiple (or all) tables, select the Tables item under the relevant database in Object Explorer. A list of all tables appears in the Object Explorer Details window. Select the tables you want to script (using the Control key if necessary) and then right click and select which script option you want – e.g. to create a table create script for all tables
Registered Servers / Central Management Server
If you have a lot of servers then re-entering the details in Object Explorer every time you start SSMS can be frustrating and time consuming. Fortunately there are two facilities within SSMS that enable these details to be entered just once and “remembered” each time you open up SSMS. These two facilities are Registered Servers and Central Management Servers. These were introduced in different versions of SQL Server and work in different ways, each has its own advantages and disadvantages so you may want to use both.
To add a registered server open the Registered Servers window from the View menu (or click CTRL + ALT + G), the window should appear in the top left corner of SSMS. Right click on the Local Server Groups folder and select ‘New Server Registration…’. Enter the server details and close the window. This new server should then appear under Local Server Groups, you can then right click and open up the server in Object Explorer or open a new query window. The server details are stored locally in an XML file and so will appear next time you open SSMS. If you have a lot of servers then you can also create Server Groups to group together similar servers. One advantage of creating groups (other than being able to logically group similar servers together) is that you can run a query against all servers in the group, by right clicking the group and selecting ‘New Group’.
Central Management Server are similar to Registered Servers but with some differences, the main one being that the server details are stored in a database (the Central Management Server) rather than a local file. A significant limitation with CMS is that the CMS server itself can’t be included in the list of servers.
Splitting the Query Window
The query window in SSMS can be split into two so that you can look at two parts of the same query simultaneously. Both parts of the split window can be scrolled independently. This is especially useful if you have a large query and want to compare different areas of the same query. To split the window simply drag the bar to the top right hand side of the window as shown below.
The splitter bar allows you to view one session with two panes. You can scroll in each pane independently. You can also edit in both the top and bottom pane.
Moving columns in the results pane
It may not be immediately obvious but you can switch columns around in the results pane when using the grid view, by dragging the column headers and dropping them next to another column header. This can be useful if you want to rearrange how the results are displayed without amending the query, especially if you have a lot of columns in your result set. This works only for one column.
Generating Charts and Drawings in SQL Server Management Studio
You don’t have to settle for T-SQL’s monochrome text output. These stored procedures let you quickly and easily turn your SELECT queries’ output into colorized charts and even computer-generated art. To turn your own data into a line, column, area, or bar chart using the Chart stored procedure, you need to design a SELECT query that serves as the first parameter in the stored procedure call.
One such change SSMS got for free is the connection resiliency logic within the SqlConnection.Open() method. To improve the default experience for clients which connect to Azure SQL Database, the above method will (in the case of initial connection errors / timeouts) now retry 1 time after sleeping for 10 seconds. These numbers are configurable by properties called ConnectRetryCount (default value 1) and ConnectRetryInterval (default value 10 seconds.) The previous versions of the SqlConnection class would not automatically retry in cases of connection failure.
There is a simple workaround for this situation. It is to add the following parameter string into the Additional Connection Parameters tab within the SSMS connection window. The good news is that you only need to do this once, as the property is saved for future sessions for that SQL Server (until of course it is removed by you later.)
ConnectRetryCount=0
Working with tabs headers
You can view SPID in tabs header, quickly open script containing folder or copy script file path.
Hiding tables in SSMS Object Explorer
You can actually hide an object from object explorer by assigning a specific extended property:
Now UserName won’t be able to see Table in Object Explorer. In Fact, they won’t be able to see the table in sys.tables or INFORMATION_SCHEMA.TABLES
VIEW DEFINITION is the ability to see the definition of the object. In the case of SPs the code, same with Views and in the case of Tables it’s the columns definitions etc.
UnDock Tabs and Windows for Multi Monitor Support
From SSMS 2012 and onwards, you can easily dock/undock the query tabs as well as different object windows inside SSMS to make better use of the screen real estate and multiple monitors you have.
RegEx-Based Finding and Replacing of Text in SSMS
So often, one sees developers doing repetitive coding in SSMS or Visual Studio that would be much quicker and easier by using the built-in Regular-Expression-based Find/Replace functionality. It is understandable, since the syntax is odd and some features are missing, but it is still well-worth knowing about.
My favorite regex: replace \t on \n,. It useful in many cases when you have column names copied from, for example, Excel and need quickly get sql query.
Changing what SSMS opens on startup
You can customize SSMS startup behavior in Tools -> Options -> Environment -> Startup and hide system objects in Object Explore:
Also you can disable the splash screen – this cuts the time it takes SSMS to load for versions before SSMS 17. Right click your shortcut to SSMS and select properties. Enter the text -nosplash right after the ending quote in the path:
It is useful to create a solution of commonly used SQL scripts to always load at start-up.
Display the Solution Explorer by pressing Ctrl+Alt+L or clicking View -> Solution Explorer.
Then right click the Solution "Solution1" (0 projects) text and select Add -> New Project.
Use the default SQL Server Scripts template and give your solution a clever name.
Rename all of your SQL Code Snippets so the extension is .SQL. Drag them into the queries folder within the Solution Explorer.
Open Windows explorer and browse to the location of your solution. Copy file location address to your clipboard. Go back to your SSMS shortcut properties and add within double quotes the location and file name of your solution before the “-nosplash”.
This is the complete text within my shortcut properties:
"C:\Program Files (x86)\Microsoft SQL Server\140\Tools\Binn\ManagementStudio\Ssms.exe" "C:\Users\taranov\Documents\SQL Server Management Studio\Projects\MySQLServerScripts.ssmssln" -nosplash
Modifying New Query Template
You can modified New Query template for any instance SQL Server:
The options represent the SET values of the current session. SET options can affect how the query is execute thus having a different execution plan. You can find these options in two places within SSMS under Tools -> Options -> Query Execution -> SQL Server -> Advanced:
As well as Tools -> Options -> Query Execution -> SQL Server -> ANSI:
Using the interface to check what is set can get tiresome. Instead, you can use the system function @@OPTIONS. Each option shown above has a BIT value for all 15 options indicating whether or not it is enabled.
@@OPTIONS takes the binary representation and does a BITWISE operation on it to produce an integer value based on the sum of which BITS are enabled.
Default value for SELECT @@OPTIONS is 5496. Let’s assume for a moment that the only two options that are enabled on my machine are ANSI_PADDING and ANSI_WARNINGS. The values for these two options are 8 and 16, respectively speaking. The sum of the two is 24.
/*************************************************************** Author: John Morehouse Summary: This script display what SET options are enabled for the current session. You may alter this code for your own purposes. You may republish altered code as long as you give due credit. THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE.***************************************************************/SELECT'Disable_Def_Cnst_Chk'AS'Option', CASE @@options & 1 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'IMPLICIT_TRANSACTIONS'AS'Option', CASE @@options & 2 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'CURSOR_CLOSE_ON_COMMIT'AS'Option', CASE @@options & 4 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ANSI_WARNINGS'AS'Option', CASE @@options & 8 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ANSI_PADDING'AS'Option', CASE @@options & 16 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ANSI_NULLS'AS'Option', CASE @@options & 32 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ARITHABORT'AS'Option', CASE @@options & 64 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ARITHIGNORE'AS'Option', CASE @@options & 128 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'QUOTED_IDENTIFIER'AS'Option', CASE @@options & 256 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'NOCOUNT'AS'Option', CASE @@options & 512 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ANSI_NULL_DFLT_ON'AS'Option', CASE @@options & 1024 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'ANSI_NULL_DFLT_OFF'AS'Option', CASE @@options & 2048 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'CONCAT_NULL_YIELDS_NULL'AS'Option', CASE @@options & 4096 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'NUMERIC_ROUNDABORT'AS'Option', CASE @@options & 8192 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled'UNION ALLSELECT'XACT_ABORT'AS'Option', CASE @@options & 16384 WHEN 0 THEN 0 ELSE 1 END AS'Enabled/Disabled';
SQL Server Diagnostics Extension
Analyze Dumps – Customers using this extension will be able to debug and self-resolve memory dump issues from their SQL Server instances and receive recommended Knowledge Base (KB) article(s) from Microsoft, which may be applicable for the fix. The memory dumps are stored in a secured and compliant manner as governed by the Microsoft Privacy Policy.
For example, Joe, a DBA from Contoso, Ltd., finds that SQL Server has generated a memory dump while running a workload, and he would like to debug the issue. Using this feature, John can upload the dump and receive recommended KB articles from Microsoft, which can help him fix the issue.
One of my favorite things about Python is that users get the benefit of observing the R community and then emulating the best parts of it. I’m a big believer that a language is only as helpful as its libraries and tools.
This post is about pandasql, a Python package we (Yhat) wrote that emulates the R package sqldf. It’s a small but mighty library comprised of just 358 lines of code. The idea of pandasql is to make Python speak SQL. For those of you who come from a SQL-first background or still “think in SQL”, pandasql is a nice way to take advantage of the strengths of both languages.
In this introduction, we’ll show you to get up and running with pandasql inside of Rodeo, the integrated development environment (IDE) we built for data exploration and analysis. Rodeo is an open source and completely free tool. If you’re an R user, its a comparable tool with a similar feel to RStudio. As of today, Rodeo can only run Python code, but last week we added syntax highlighting for a bunch of other languages to the editor (markdown, JSON, julia, SQL, markdown). As you may have read or guessed, we’ve got big plans for Rodeo, including adding SQL support so that you can run your SQL queries right inside of Rodeo, even without our handy little pandasql. More on that in the next week or two!
ps If you download Rodeo and encounter a problem or simply have a question, we monitor our discourse forum 24/7 (okay, almost).
A bit of background, if you’re curious
Behind the scenes, pandasql uses the pandas.io.sql module to transfer data between DataFrame and SQLite databases. Operations are performed in SQL, the results returned, and the database is then torn down. The library makes heavy use of pandaswrite_frame and frame_query, two functions which let you read and write to/from pandas and (most) any SQL database.
Install pandasql
Install pandasql using the package manager pane in Rodeo. Simply search for pandasql and click Install Package.
You can also run ! pip install pandasql from the text editor if you prefer to install that way.
Check out the datasets
pandasql has two built-in datasets which we’ll use for the examples below.
meat: Dataset from the U.S. Dept. of Agriculture containing metrics on livestock, dairy, and poultry outlook and production
births: Dataset from the United Nations Statistics Division containing demographic statistics on live births by month
Run the following code to check out the data sets.
#Checking out meat and birth data
from pandasql import sqldf
from pandasql import load_meat, load_births
meat = load_meat()
births = load_births()
#You can inspect the dataframes directly if you're using Rodeo
#These print statements are here just in case you want to check out your data in the editor, too
print meat.head()
print births.head()
Inside Rodeo, you really don’t even need the print.variable.head() statements, since you can actually just examine the dataframes directly.
An odd graph
# Let's make a graph to visualize the data
# Bet you haven't had a title quite like this before
import matplotlib.pyplot as plt
from pandasql import *
import pandas as pd
pysqldf = lambda q: sqldf(q, globals())
q = """
SELECT
m.date
, m.beef
, b.births
FROM
meat m
LEFT JOIN
births b
ON m.date = b.date
WHERE
m.date > '1974-12-31';
"""
meat = load_meat()
births = load_births()
df = pysqldf(q)
df.births = df.births.fillna(method='backfill')
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(pd.rolling_mean(df['beef'], 12), color='b')
ax1.set_xlabel('months since 1975')
ax1.set_ylabel('cattle slaughtered', color='b')
ax2 = ax1.twinx()
ax2.plot(pd.rolling_mean(df['births'], 12), color='r')
ax2.set_ylabel('babies born', color='r')
plt.title("Beef Consumption and the Birth Rate")
plt.show()
Notice that the plot appears both in the console and the plot tab (bottom right tab).
Tip: You can “pop out” your plot by clicking the arrows at the top of the pane. This is handy if you’re working on multiple monitors and want to dedicate one just to your data visualzations.
Usage
To keep this post concise and easy to read, we’ve just given the code snippets and a few lines of results for most of the queries below.
If you’re following along in Rodeo, a few tips as you’re getting started:
Run Script will indeed run everything you have written in the text editor
You can highlight a code chunk and run it by clicking Run Line or pressing Command + Enter
You can resize the panes (when I’m not making plots I shrink down the bottom right pane)
Basics
Write some SQL and execute it against your pandasDataFrame by substituting DataFrames for tables.
pandasql creates a DB, schema and all, loads your data, and runs your SQL.
Aggregation
pandasql supports aggregation. You can use aliased column names or column numbers in your group byclause.
# births per year
q = """
SELECT
strftime("%Y", date)
, SUM(births)
FROM births
GROUP BY 1
ORDER BY 1;
"""
print sqldf(q, locals())
# strftime("%Y", date) SUM(births)
# 0 1975 3136965
# 1 1976 6304156
# 2 1979 3333279
# 3 1982 3612258
locals() vs. globals()
pandasql needs to have access to other variables in your session/environment. You can pass locals() to pandasql when executing a SQL statement, but if you’re running a lot of queries that might be a pain. To avoid passing locals all the time, you can add this helper function to your script to set globals() like so:
# joining meats + births on date
q = """
SELECT
m.date
, b.births
, m.beef
FROM
meat m
INNER JOIN
births b
on m.date = b.date
ORDER BY
m.date
LIMIT 100;
"""
joined = pysqldf(q)
print joined.head()
#date births beef
#0 1975-01-01 00:00:00.000000 265775 2106.0
#1 1975-02-01 00:00:00.000000 241045 1845.0
#2 1975-03-01 00:00:00.000000 268849 1891.0
WHERE conditions
Here’s a WHERE clause.
q = """
SELECT
date
, beef
, veal
, pork
, lamb_and_mutton
FROM
meat
WHERE
lamb_and_mutton >= veal
ORDER BY date DESC
LIMIT 10;
"""
print pysqldf(q)
# date beef veal pork lamb_and_mutton
# 0 2012-11-01 00:00:00 2206.6 10.1 2078.7 12.4
# 1 2012-10-01 00:00:00 2343.7 10.3 2210.4 14.2
# 2 2012-09-01 00:00:00 2016.0 8.8 1911.0 12.5
# 3 2012-08-01 00:00:00 2367.5 10.1 1997.9 14.2
It’s just SQL
Since pandasql is powered by SQLite3, you can do most anything you can do in SQL. Here are some examples using common SQL features such as subqueries, order by, functions, and unions.
#################################################
# SQL FUNCTIONS
# e.g. `RANDOM()`
#################################################
q = """SELECT
*
FROM
meat
ORDER BY RANDOM()
LIMIT 10;"""
print pysqldf(q)
# date beef veal pork lamb_and_mutton broilers other_chicken turkey
# 0 1967-03-01 00:00:00 1693 65 1136 61 472.0 None 26.5
# 1 1944-12-01 00:00:00 764 146 1013 91 NaN None NaN
# 2 1969-06-01 00:00:00 1666 50 964 42 573.9 None 85.4
# 3 1983-03-01 00:00:00 1892 37 1303 36 1106.2 None 182.7
#################################################
# UNION ALL
#################################################
q = """
SELECT
date
, 'beef' AS meat_type
, beef AS value
FROM meat
UNION ALL
SELECT
date
, 'veal' AS meat_type
, veal AS value
FROM meat
UNION ALL
SELECT
date
, 'pork' AS meat_type
, pork AS value
FROM meat
UNION ALL
SELECT
date
, 'lamb_and_mutton' AS meat_type
, lamb_and_mutton AS value
FROM meat
ORDER BY 1
"""
print pysqldf(q).head(20)
# date meat_type value
# 0 1944-01-01 00:00:00 beef 751
# 1 1944-01-01 00:00:00 veal 85
# 2 1944-01-01 00:00:00 pork 1280
# 3 1944-01-01 00:00:00 lamb_and_mutton 89
#################################################
# subqueries
# fancy!
#################################################
q = """
SELECT
m1.date
, m1.beef
FROM
meat m1
WHERE m1.date IN
(SELECT
date
FROM meat
WHERE
beef >= broilers
ORDER BY date)
"""
more_beef_than_broilers = pysqldf(q)
print more_beef_than_broilers.head(10)
# date beef
# 0 1960-01-01 00:00:00 1196
# 1 1960-02-01 00:00:00 1089
# 2 1960-03-01 00:00:00 1201
# 3 1960-04-01 00:00:00 1066
Final thoughts
pandas is an incredible tool for data analysis in large part, we think, because it is extremely digestible, succinct, and expressive. Ultimately, there are tons of reasons to learn the nuances of merge, join, concatenate, melt and other native pandas features for slicing and dicing data. Check out the docs for some examples.
Our hope is that pandasql will be a helpful learning tool for folks new to Python and pandas. In my own personal experience learning R, sqldf was a familiar interface helping me become highly productive with a new tool as quickly as possible.
And now, in a break from the previous trend of fluffy posts, we have a tutorial on how to (deep breath): connect PHP to a MSSQL Server 2008 instance over ODBC from Ubuntu Linux using the FreeTDS driver and unixODBC. Theoretically it would also work for SQL Server 2005.
I don’t know whether half of the settings flags are necessary or even correct, but what follows Worked for Me™, YMMV, etc, etc.
In the commands below, I’ll use 192.168.0.1 as the server housing the SQL Server instance, with a SQL Server user name of devuser, password devpass. I’m assuming SQL Server is set up to listen on its default port, 1433. Keep an eye out, because you’ll need to change these things to your own settings.
First, install unixODBC:
sudo apt-get install unixodbc unixodbc-dev
I also installed the following (perhaps necessary) packages: sudo apt-get install tdsodbc php5-odbc
Then download, untar, compile, and install FreeTDS (warning, the URL may change): cd /usr/local
wget http://ibiblio.org/pub/Linux/ALPHA/freetds/stable/freetds-stable.tgz
tar xvfz freetds-stable.tgz
cd freetds-0.82
./configure --enable-msdblib --with-tdsver=8.0 --with-unixodbc=/usr
make
make install
make clean
Attempt a connection over Telnet to your SQL Server instance: telnet 192.168.0.1 1433
Use the tsql tool to test out the connection: tsql -S 192.168.0.1 -U devuser
This should prompt you for the password, after which you can hope against hope to see this beautiful sign: 1>
If that worked, I recommend throwing a (coding) party. Next up is some configging. Open the FreeTDS config file. /usr/local/etc/freetds.conf
Add the following entry to the bottom of the file. We’re setting up a datasource name (DSN) called ‘MSSQL’. [MSSQL]
host = 192.168.0.1
port = 1433
tds version = 8.0
Now open the ODBC configuration file: /usr/local/etc/odbcinst.ini
And add the following MSSQL driver entry (FreeTDS) at the end: [FreeTDS]
Description = FreeTDS driver
Driver = /usr/local/lib/libtdsodbc.so
Setup=/usr/lib/odbc/libtdsS.so
FileUsage = 1
UsageCount = 1
Then, finally, set up the DSN within ODBC in the odbc.ini file here /usr/local/etc/odbc.ini
By adding this bit to the file: [MSSQL]
Description = MS SQL Server
Driver = /usr/local/lib/libtdsodbc.so
Server = 192.168.2.3
UID = devuser
PWD = devpass
ReadOnly = No
Port = 1433
Test out the connection using the isql tool: isql -v MSSQL devuser 'devpass'
If you see “Connected!” you’re golden, congratulations! If not, I’m truly sorry; see below where there are some resources that might help.
Now restart Apache and test it from PHP using ‘MSSQL’ as the DSN. If something doesn’t work, you might try installing any or all of these packages: mdbtools libmdbodbc libmdbtools mdbtools-gmdb
Here are some other resources that were helpful to me through this disastrous journey.
select * from
(
select name,class,s,rank()over(partition by class order by s desc) mm from t2
)
where mm=1;
得到的结果是:
dss 1 95 1
ffd 1 95 1
gds 2 92 1
gf 3 99 1
ddd 3 99 1
注意:
1.在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果;
select * from
(
select name,class,s,row_number()over(partition by class order by s desc) mm from t2
)
where mm=1;
1 95 1 –95有两名但是只显示一个
2 92 1
3 99 1 –99有两名但也只显示一个
2.rank()和dense_rank()可以将所有的都查找出来:
如上可以看到采用rank可以将并列第一名的都查找出来;
rank()和dense_rank()区别:
–rank()是跳跃排序,有两个第二名时接下来就是第四名;
select name,class,s,rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 3 –直接就跳到了第三
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 3
asdf 3 55 4
adf 3 45 5
–dense_rank()l是连续排序,有两个第二名时仍然跟着第三名
select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 2 –连续排序(仍为2)
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 2
asdf 3 55 3
adf 3 45 4
–sum()over()的使用
select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 –根据班级进行分数求和
dss 1 95 190 –由于两个95都是第一名,所以累加时是两个第一名的相加
ffd 1 95 190
fda 1 80 270 –第一名加上第二名的
gds 2 92 92
cfe 2 74 166
gf 3 99 198
ddd 3 99 198
3dd 3 78 276
asdf 3 55 331
adf 3 45 376
first_value() over()和last_value() over()的使用
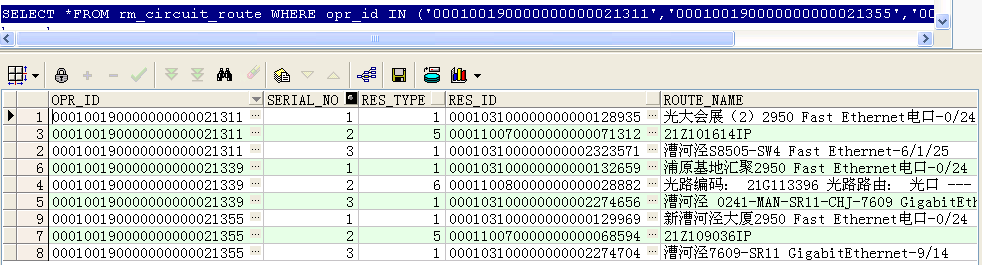
–找出这三条电路每条电路的第一条记录类型和最后一条记录类型
SELECT opr_id,res_type,
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type rows BETWEEN unbounded preceding AND unbounded following) high
FROM rm_circuit_route
WHERE opr_id IN (‘000100190000000000021311′,’000100190000000000021355′,’000100190000000000021339’)
ORDER BY opr_id;
注:rows BETWEEN unbounded preceding AND unbounded following 的使用
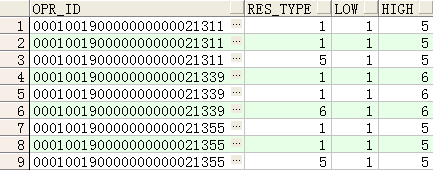
–取last_value时不使用rows BETWEEN unbounded preceding AND unbounded following的结果
SELECT opr_id,res_type,
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) high
FROM rm_circuit_route
WHERE opr_id IN (‘000100190000000000021311′,’000100190000000000021355′,’000100190000000000021339’)
ORDER BY opr_id;
如下图可以看到,如果不使用
rows BETWEEN unbounded preceding AND unbounded following,取出的last_value由于与res_type进行进行排列,因此取出的电路的最后一行记录的类型就不是按照电路的范围提取了,而是以res_type为范围进行提取了。
–lag() over()函数用法(取出前n行数据) lag(expresstion,<offset>,<default>)
with a as
(select 1 id,’a’ name from dual
union
select 2 id,’b’ name from dual
union
select 3 id,’c’ name from dual
union
select 4 id,’d’ name from dual
union
select 5 id,’e’ name from dual
)
select id,name,lag(id,1,”)over(order by name) from a;
–lead() over()函数用法(取出后N行数据)
lead(expresstion,<offset>,<default>)
with a as
(select 1 id,’a’ name from dual
union
select 2 id,’b’ name from dual
union
select 3 id,’c’ name from dual
union
select 4 id,’d’ name from dual
union
select 5 id,’e’ name from dual
)
select id,name,lead(id,1,”)over(order by name) from a;
–ratio_to_report(a)函数用法 Ratio_to_report() 括号中就是分子,over() 括号中就是分母
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over(partition by a) b from a
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a –分母缺省就是整个占比
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a
group by a order by a;–分组后的占比
percent_rank用法
计算方法:所在组排名序号-1除以该组所有的行数-1,如下所示自己计算的pr1与通过percent_rank函数得到的值是一样的:
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
(a.r-1)/(n-1) pr1,
percent_rank() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r –计算出在组中的排名序号
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b –按部门计算每个部门的所有成员数
WHERE a.deptno = b.deptno;
cume_dist函数
计算方法:所在组排名序号除以该组所有的行数,但是如果存在并列情况,则需加上并列的个数-1,
如下所示自己计算的pr1与通过percent_rank函数得到的值是一样的:
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
c.rn,
(a.r + c.rn – 1) / n pr1,
cume_dist() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b,
(SELECT deptno, r, COUNT(1) rn,sal
FROM (SELECT deptno,sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp)
GROUP BY deptno, r,sal
ORDER BY deptno) c –c表就是为了得到每个部门员工工资的一样的个数
WHERE a.deptno = b.deptno
AND a.deptno = c.deptno(+)
AND a.sal = c.sal;
percentile_cont函数
含义:输入一个百分比(该百分比就是按照percent_rank函数计算的值),返回该百分比位置的平均值
如下,输入百分比为0.7,因为0.7介于0.6和0.8之间,因此返回的结果就是0.6对应的sal的1500加上0.8对应的sal的1600平均
SELECT ename,
sal,
deptno,
percentile_cont(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) “Percentile_Cont”,
percent_rank() over(PARTITION BY deptno ORDER BY sal) “Percent_Rank”
FROM emp
WHERE deptno IN (30, 60);
若输入的百分比为0.6,则直接0.6对应的sal值,即1500
SELECT ename,
sal,
deptno,
percentile_cont(0.6) within GROUP(ORDER BY sal) over(PARTITION BY deptno) “Percentile_Cont”,
percent_rank() over(PARTITION BY deptno ORDER BY sal) “Percent_Rank”
FROM emp
WHERE deptno IN (30, 60);
SELECT ename,
sal,
deptno,
percentile_disc(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) “Percentile_Disc”,
cume_dist() over(PARTITION BY deptno ORDER BY sal) “Cume_Dist”
FROM emp
WHERE deptno IN (30, 60);
AutoMapper: 自动生成对象到对象的映射代码,比如,能够生成从实体对象映射到域对象,而不是手动编写映射代码。Object to object mapping. Like, the tool can be used to map entity objects to domain objects instead of writing manual mapping code.
StyleCop: StyleCop 是静态代码分析工具,能够统一设置代码样式和规范。 可以在Visual Studio 中使用,也可以集成到 MSBuild 项目。
FxCop: FxCop 是静态代码分析工具,能够通过分析.Net 程序集保证开发标准。
运行状况捕获
WireShark: It is a network protocol analyzer for Unix and Windows. It can capture traffic at TCP level.
HTTP Monitor: enables the developer to view all the HTTP traffic between your computer and the Internet. This includes the request data (such as HTTP headers and form GET and POST data) and the response data (including the HTTP headers and body).